Introduction
Split is a platform for configuring and analyzing experiments. At GoDaddy, we’re building an experimentation platform leveraging Split as the configuration GUI and bucketing engine while layering more advanced and GoDaddy-specific features on top of the experimentation capabilities already available within Split. One challenge with experiment bucketing is that the time spent to get the library ready, which involves downloading the experiment definitions at page load time, might impact the KPIs you’re trying to optimize. For example, Google has run experiments demonstrating that introducing 100 milliseconds to web search causes the daily number of searches per user to drop by 0.2%. Given this potential impact, we joined forces with Split to design and implement an open-source solution that would allow us to get the benefits of an experimentation platform with no performance penalty.
Problem
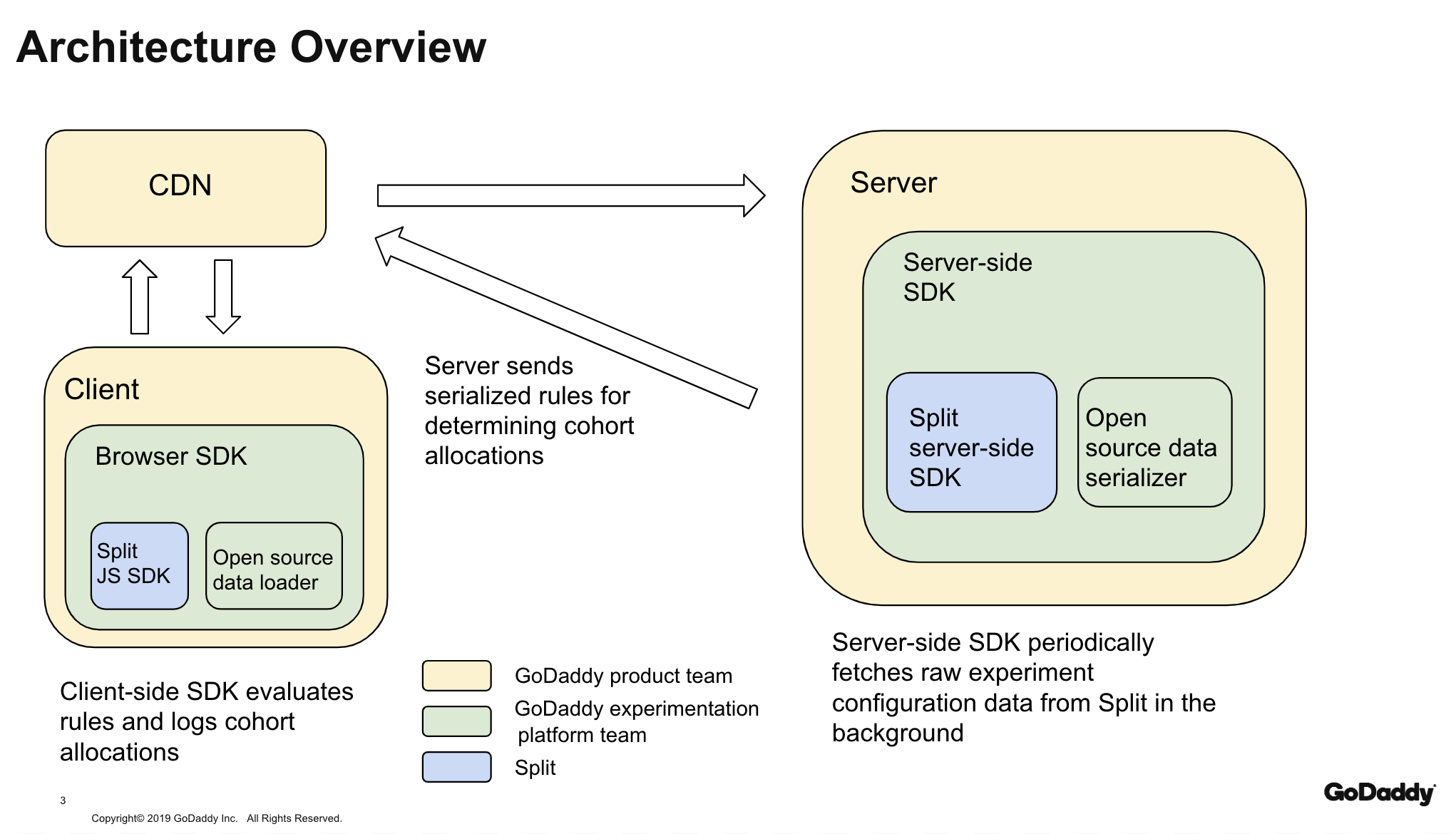
Some applications at GoDaddy store static HTML and other assets in a CDN, like Akamai, to optimize Time To Interactive (TTI). We wanted to integrate those applications with our experimentation platform, but since experiment cohort assignments are user-specific, the integration options we had available would have lost the benefit of caching. To maintain a low TTI, these apps should be able to continue serving their assets from a CDN and to fetch experiment cohort allocations with low latency.
Our requirements for a solution included:
- Performance:
- computation time less than 1ms
- negligible network latency
- Simple instantiation
The initial set of solutions we explored would all add latency to applications or overhead to our partners, limiting the kinds of experiments we could run and adding friction to broad adoption.
Ideas we considered for fetching experiment bucket assignments client-side, but then rejected:
- Stand up a REST API – while a REST API is generalizable across different architectures and is easy for teams to onboard to, the performance impact would be greater than our 1ms SLA, and what engineering team wants to be on-call for another service if they can avoid it!?
- Provision Lambda functions – we could spin up Lambdas for partner teams to use to get cohort allocations. This method would add partner overhead (upfront cost of creating resources and ongoing cost of monitoring) and is still not as fast as we’d like.
- Use a browser SDK – we could use the existing Split JavaScript SDK. It would require little engineering work, but this approach would include a network call back to Split’s CDN from the client, resulting in a minor but noticeable performance hit (~ < 200 milliseconds).
Solution
We shared requirements with the team at Split and proposed an idea to separate raw configuration (data outlining experiments like cohorts, targeting rules, and split percentages) from decisioning (the point at which a user is assigned to a cohort for a particular experiment). This approach avoids any network call from the browser, works with edge caching because no user-specific information is sent to the browser, and decisions in microseconds. Split provided a design spec, and we both contributed to a set of tools that let us co-locate raw configuration alongside GoDaddy teams’ cached pages at the CDN layer.
Server-side
On the server-side, to keep cache benefits, we needed a response that is not user-specific. One of the advantages of using Split is that experiment targeting happens on the client side, so the server can respond with a generic payload.
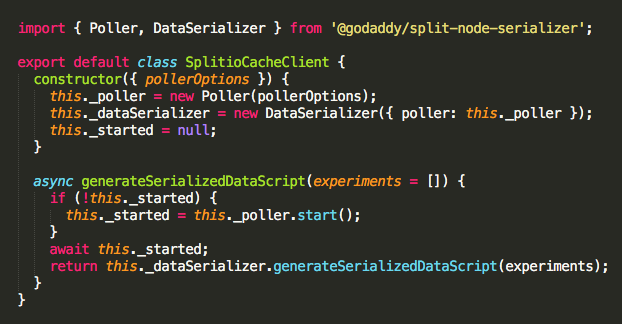
To do this, we built a small server-side tool in Node.js and Golang that periodically fetches split definitions and segments data from the Split API and serializes it into a set of strings to be uploaded to the CDN and cached alongside the page content. Those strings are subsequently consumed by the browser SDK when the page loads.
We then integrated this tool into our GoDaddy experimentation SDKs (Node.js and Golang at the moment):
Client-side
On the client, we needed to handle decisioning.
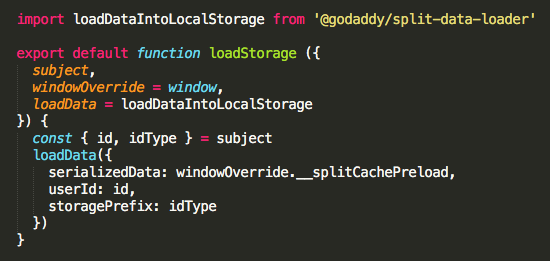
Split added an event to their JavaScript SDK that gets emitted when the SDK is configured to use LOCALSTORAGE. When the local storage cache has been loaded with split rules, this event fires. Split also updated the JavaScript SDK to support evaluation in this “ready from cache” state, thus avoiding an extra call to Split’s CDN to download the raw configuration.
We then created a JavaScript data loader to write raw configuration data into the browser’s local storage for the browser SDK to consume and built a browser SDK that invokes this data loader script and wraps around the Split JavaScript SDK:
Outcome
We first integrated this new set of experimentation tools into the domain purchase pathway - the flow GoDaddy customers go through to find and buy a domain name.
We ran A/A tests on each application in that flow to ensure that having the tooling in place would do no harm and that the pieces were working end-to-end.
Since then, we’ve launched the first A/B test using this solution on the cart page, resulting in an increased conversion rate.
What’s next?
- Split will incorporate our open-source data serializer and data loader libraries into the official Split SDKs
- We will continue onboarding teams to the experimentation platform
How to contribute
- Node.js data serializer: https://github.com/godaddy/split-node-serializer
- Golang data serializer: https://github.com/godaddy/split-go-serializer
- JavaScript data loader: https://github.com/godaddy/split-javascript-data-loader
Careers at GoDaddy
We’re hiring a senior engineer and engineering manager to help grow our experimentation platform.





