GoDaddy provides best in class search experience for people looking for domain names. Search data engineering is the critical plumbing behind the seamless search experience on the GoDaddy search page. In this blog post, we provide some insights into the inner workings of the data pipelines by delving into the architecture and the implementation of the search data infrastructure.
Introduction
Most businesses or ventures start with a domain name. GoDaddy domain search plays a critical role in helping the user take this first step. Domain search is the main entry point for GoDaddy customers looking for the perfect name.
Domain search at GoDaddy, has three primary pillars:
- Back end engineering - the architecture and software engineering that maintains high availability all over the world.
- Recommendation engine - the machine learning (ML) engine that recommends personalized suggestions to the users.
- Data engineering - the transforming of the data and powering of the models and the software engineering that provides a world-class search experience.
While back end engineering and recommendation engines are widely discussed and understood in search, the role of data engineering in such systems remains an obscurely documented topic. In this article, we discuss the details of our search data architecture and pipelines, the data engineering, the ‘intelligence’ within the search pipelines, and the instrumentation of domain search that allows GoDaddy to process over 500 terabytes of over 1 billion data objects.
Bikes? Huh?
Think about a bike chain. Does a bike without a chain still work? Sure. Both the front and rear wheel can spin without a chain so a bike rider can travel downhill pretty easily. They can also have someone push them or use their feet to propel them forward manually. But it would be pretty difficult to go uphill or to travel for extended periods on flat terrain on a bike without a chain. Without a bike chain, you lose the ability to power both wheels using the pedals. Is a bike without a chain the most effective way to travel? Probably not…
Data engineering is the bike chain that connects and powers both wheels. Data engineering works in conjunction with back end engineering and the recommendation engine to give users a fully-powered search experience. With the bike chain on the bike, users don’t only need to go downhill; they can travel on any kind of terrain.
Front end search
There are two scenarios when a user searches for a domain, either the domain is available for purchase or it’s already taken. First, let’s walk through what a customer experiences when the domain is available.
(1) When looking for a domain name, a user enters a keyword or a complete name that includes the top level domain (TLD) (or ending) in the search box. The back end engineering consults the registries for the availability of the exact name and feeds the search term to the recommendation engine for personalized name suggestions.
(2) The customer’s domain of choice is presented to the customer with the price.
(3) The result of the exact match and these suggestions are surfaced as an ordered list based on relevance.
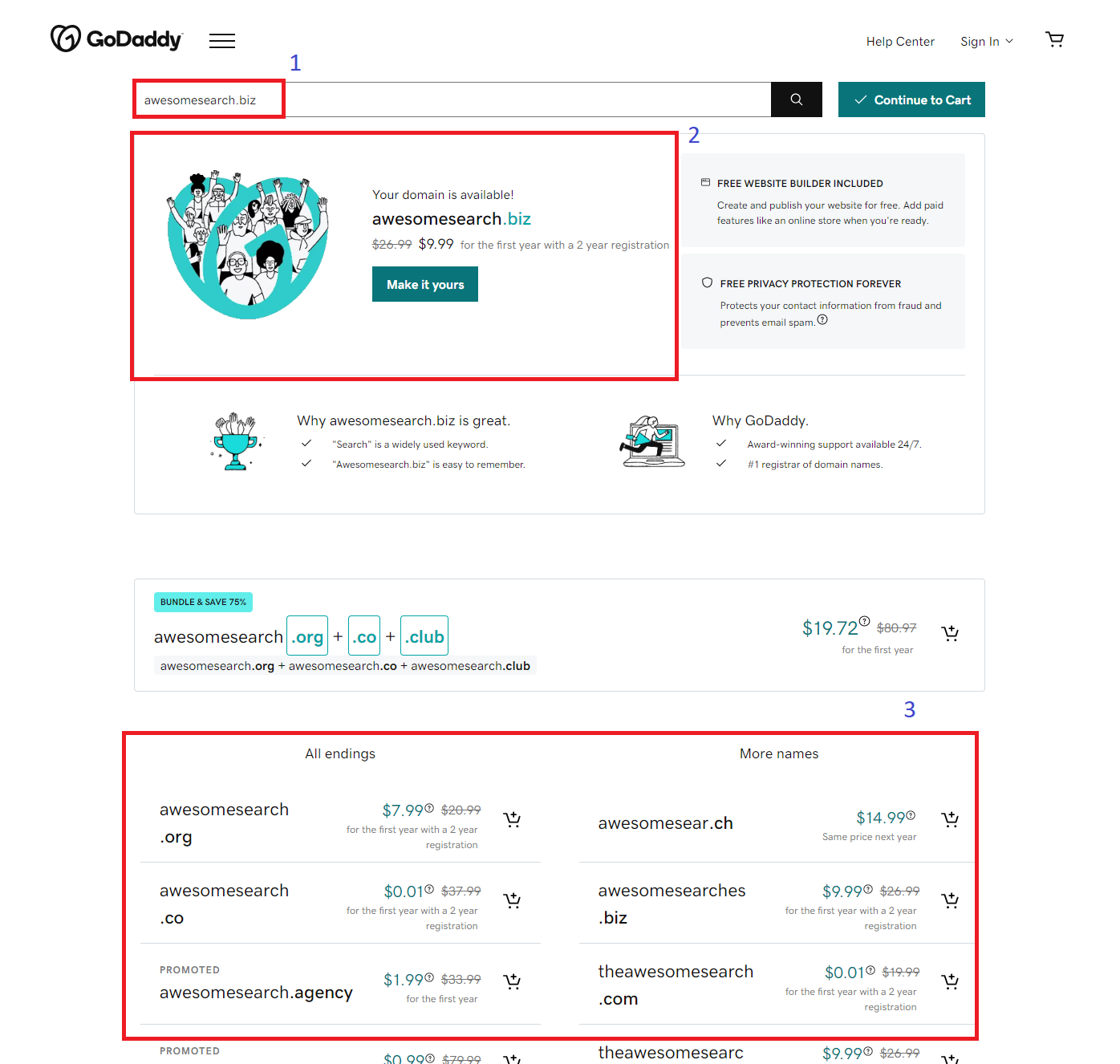
Now let’s take a look at what happens if the user’s domain of choice is already taken.
(1) The user enters a domain name in the search box.
(2) If the customer’s domain name of choice is already taken, but may be available for purchase, GoDaddy presents the expected cost to acquire the domain.
(3) Search also recommends the most relevant available at the top level with more suggestions at the bottom.
(4) The result of the exact match and these suggestions are surfaced as an ordered list based on relevance.
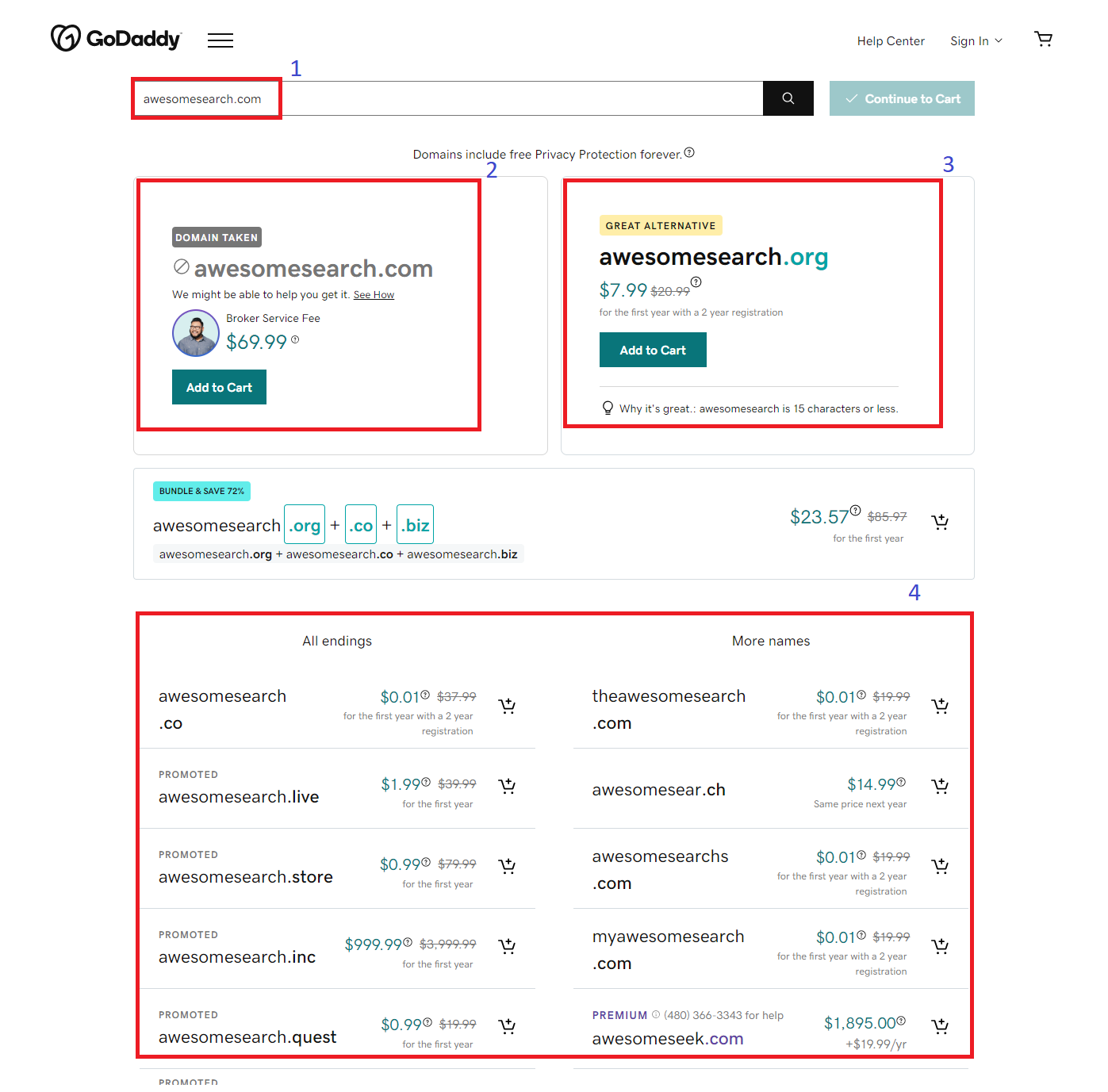
The user can purchase any of these domains from the list by adding it to their cart. Or they can continue with the search using different terms. In this whole user experience, several data points are collected and processed to provide feedback to the ML models and the back end engineering to improve the search experience.
The search lifecycle
To understand the data engineering aspect of search, we need to describe what we call the search lifecycle. The search lifecycle consists of the data engineering that produces the front end search results for the customer over the course of a domain search and purchase. The diagram below illustrates the processes involved in generating search results from a search on GoDaddy’s site.
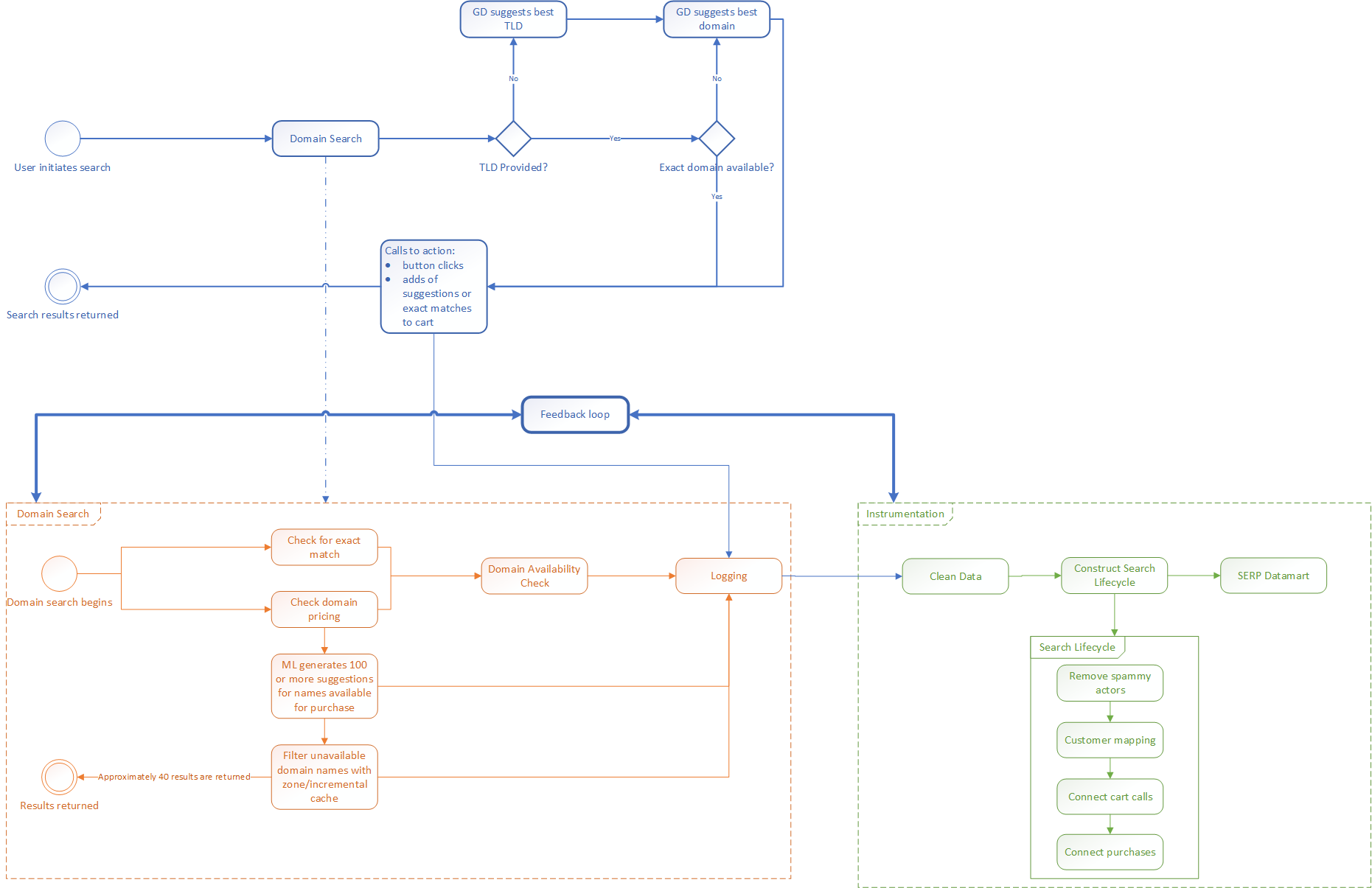
A typical GoDaddy customer will search for available domain names on an initial visit to the site, but may not make a purchase for weeks or months. In the time between their initial visit and their purchase, they may come back to the site multiple times to search for additional domain names. When a customer finally makes the purchase, they may have conducted multiple searches without ever logging in to the site. The session at the time of purchase doesn’t accurately reflect the customer’s actions or behaviors prior to making the decision to purchase the domain name they chose.
For example, let’s say a customer searches for a domain, reviews the results, selects a domain from the suggestion list, then navigates away without purchasing. They return a week later and only enter the name the domain they previously selected because they knew it was available from their previous search. Our data engineering efforts ensure that the search lifecycle is able to associate the purchase with the customer’s previous actions.
The data engineering behind the search lifecycle logs the customer’s actions (navigation, clicks, adds to their cart, etc.), creates a feedback loop for ML models, and creates a complete picture of how the person searching for a domain name became a GoDaddy customer. We’re able to construct the search lifecycle even if the user never logs in to the site.
We constantly improve the suggestions shown to the customer by continuously training the ML models with new signals and features that decide these alternative domain names. By instrumenting:
- what the customer was searching for,
- the experience the customer was offered,
- and the reaction of the customer towards the domain name suggestions,
we can effectively construct the search lifecycle. Analyzing search lifecycles across millions of customers helps us discover and use meaningful signals (or calls to action) that give us a broad picture of the quality of suggestions and customer reactions towards different experiences.
Back end search
When a customer performs a domain name search, there are multiple services in the GoDaddy search engine that work together to provide the best search experience. One component checks if the exact domain name is available for registration. If it is, the appropriate service fetches the pricing information for that domain. If the customer has only entered a name without a TLD, then additional services try to determine the best available TLD for the domain name based on customer location, past interests, and other criteria.
Whether or not the customer provides a complete domain name, the ML model generates alternative domain suggestions, but the search doesn’t check with the registries for availability when generating these alternative suggestions. Instead, to increase speed and decrease costs, the search checks psuedo zone files that contain unavailable domain names. The recommendation engine generates hundreds of candidates, but only returns approximately 40 available suggestions with their registration term and prices, along with the availability (and price, if available) of the exact match.
Other services provide suggestive domain names to the exact search performed. These services use knowledge accumulated from caches of previously owned domains and other personalized features to provide the best possible suggestive domains back to the customer. Since multiple services are used to show the best possible results to the customer, extensive instrumentation of requests and responses at every component helps in creating an end-to-end search map- the first part of the search lifecycle.
Throughout the search process, the search engine logs:
- zone responses
- suggestions returned to the customer
- calls to action (customer clicks, domain names added to the customer’s shopping cart to determine conversion rate) and
- customer mapping (ID to the actual shopper to correlate searches with purchases).
Instrumentation and categorization also help in filtering out bad or spammy threat actors which keeps our services up around the clock. We often use instrumentation as a feedback loop to gauge how our services are performing, measure response times of underlying services, and fix any unusual scenarios that surface. Instrumentation helps analyze customer engagement with alternative domain suggestions and improves the quality of the domain suggestions. This also creates a personalized experience for customers visiting GoDaddy.
Instrumentation:
- makes efficient use of data we collect and control.
- helps data scientists and business intelligence and data analysis teams obtain relevant feedback on customer behavior (like their reactions to our domain name suggestions) which leads to efficient decisions.
- groups customers (identified by visitor_id/shopper_id) that exhibit common behavior, enabling researchers to test specific data and ML models on those customer groups before testing on a varied crowd.
- acts as a feedback loop to our engineering to make better recommendations on searches and predicting experiment results.
- can be used in the personalization of customer experience on GoDaddy websites. When a customer visits search engine results pages (SERP), we can use the visitor_id stored in the cookie to get shopper_id (if the customer is logged in to GoDaddy we can obtain shopper_id directly), and with that, we can obtain a history of carted domains or purchases or even query history– all of which can lead to efficient personalized recommendations.
Search engine results page Datamart and instrumentation
The SERP is the front end UI that the user interacts with. On the back end, the SERP Datamart stores data from user interactions with SERP. The SERP Datamart listens to multiple GoDaddy endpoints related to Domain Find and Domain Search. SERP Datamart also analyzes multiple underlying data sources to provide search-level analytics. SERP Datamart then enables various correlations, (like revenue associated with each search), domains that were added to a customer’s order from a given list of domain suggestions presented to the customer, TLD-level analysis including the number of suggested second-level domains in .com and .co– along with conversion rates and revenue from each TLD, and so on. This data is surfaced as multiple tables in the data lake.
Our infrastructure has been optimized for speed and performance of SERP Datamart. We’ve monitored and re-calibrated Amazon EC2 instance sizes, pyspark configuration parameters, and data caching and page swapping. We collect our data pipeline metrics, and constantly find ways to improve on them.
Data collection and processing
Of course data collection and processing are important steps in creating the search lifecycle and generating search results for a customer. The diagram below illustrates the services involved in data collection and processing.
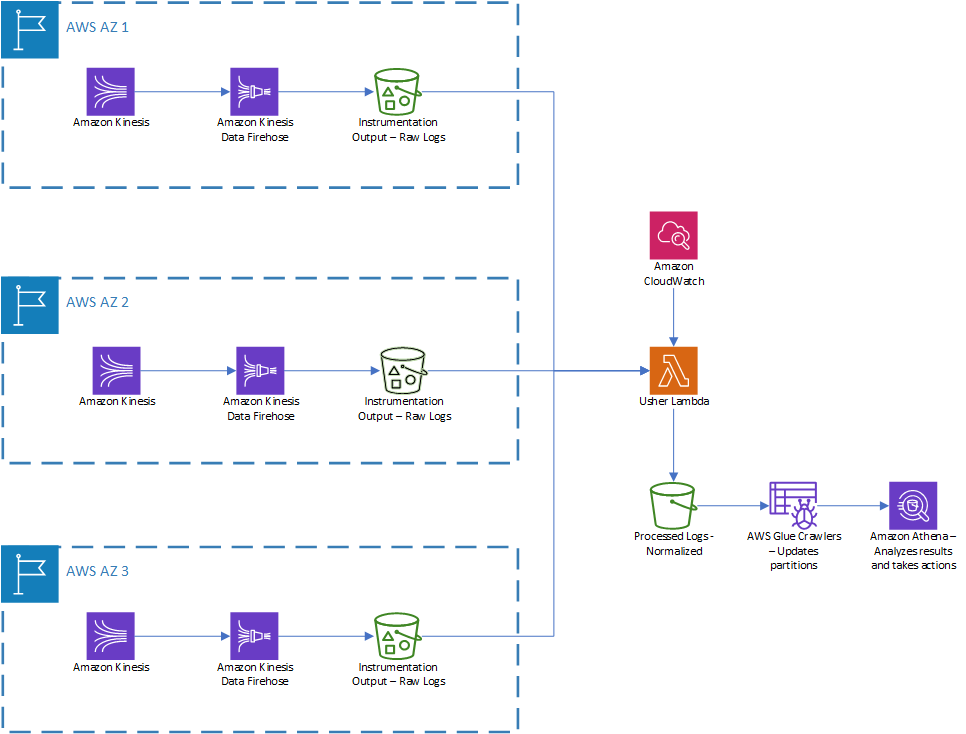
GoDaddy deploys copies of the services in multiple regions around the world. For better instrumentation, we deploy the required artifacts and infrastructure in the region closest to the customer using an AWS Lambda function we’ve named Usher.
In the collection phase, all services continuously write the requests and responses to Amazon Kinesis streams. These streams relay log files to the Amazon Kinesis Data Firehose components that buffer logs into files of 128MB or for 5 minutes, whichever comes sooner. Firehouse delivers the log files to AWS Simple Cloud Storage (S3) buckets.
In the processing phase, an Amazon CloudWatch event invokes an Usher every 10 mins. Every two hours, Usher checks for new objects in the S3 buckets that have landed. If Usher finds new objects, it uses a collection of schema files and converts them to an Optimized Raw Columnar (ORC) file, a columnar format. If Usher can’t apply a proper schema for an object, then it writes to an error partition of the output S3 bucket. These objects are processed later with a proper schema.
An AWS Glue crawler crawls the output S3 bucket’s ORC files, creates a table, and updates all partitions of data. Data pipelines are built to consume these raw logs and create the DataMart. The data process pipeline consumes raw logs from different APIs and listens for different signals (for example, read logs of all services). Finally, the data pipeline constructs one search, processes the customer’s cart and purchase signals, and associates them to the constructed search to complete the lifecycle.
Conclusion
Search is a pretty well covered topic, but missing from the discussion of search is data engineering. In the domains space, we do data engineering in search like no one else can. It’s part of the reason why we’re the world’s largest domain registrar.
While some of the larger tech companies like Google, Facebook, and Amazon probably have similar capabilities, no one in the domains space can do what we do. Even our competitors use our search functionality! No one wants to ride a bike without a chain…
If you want to be part of an awesome team that works to solve problems and build solutions for millions of small businesses, check out our current open roles.
Cover Photo Attribution: Photo by Jani Brumat on Unsplash