
Re:amaze is a GoDaddy product. It's a tool that helps businesses manage all their customer communications in a single inbox.
Customers may reach out to the business in various ways including webchat, email, phone, text, and social media messages, and Re:amaze aggregates all this in one place. For high volume businesses managing all this communication, accurate and reliable search features are important so that they provide the best customer service possible.
For years, the Re:amaze team at GoDaddy had been using a self-hosted search service to power the inbox search capabilities. That service produced accurate and quick results. However, as the product grew, managing search indices became difficult and the service would experience intermittent crashes. We needed something more reliable. This post discusses how the team adopted Elasticsearch as the new search service.
Searching in the inbox
The following image is the Re:amaze inbox.
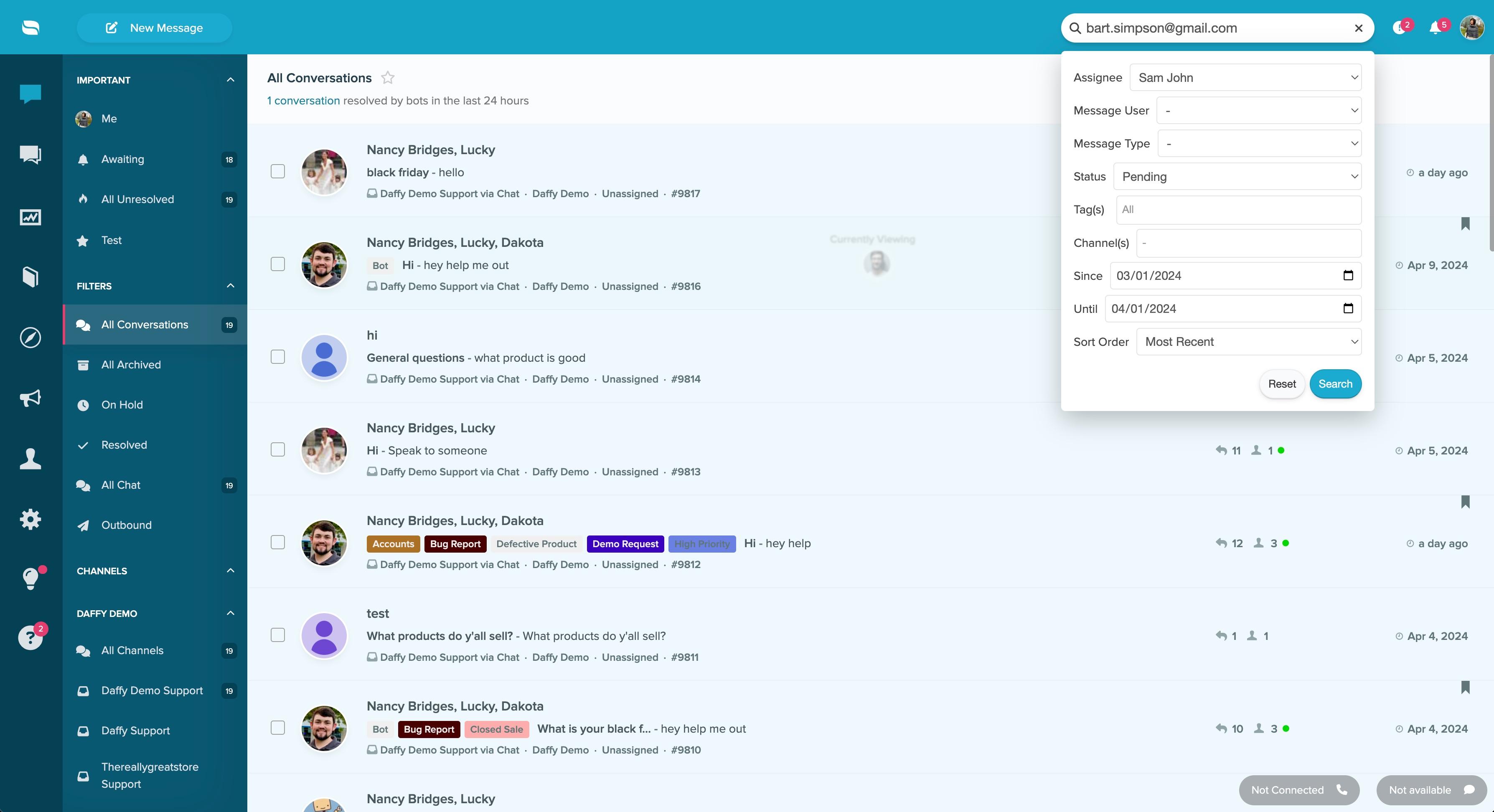
The inbox looks similar to any popular email inbox. It has folders representing different communication channels and message statuses. Then there are the messages in the center. On the right side is the search section. We'll be focusing on the search section.
The search section has many frequently used features. Users can:
- Search text in combination with filters for:
- Instagram messages only.
- Specific date range.
- Specific tags.
- Only unresolved messages.
- Search email addresses and phone numbers by prefix or infix.
- Search exact phrases or all words specified.
- Ignore unimportant stop words.
- Highlight the search hits.
Any search solution requires the building and maintenance of search indices, which are derived from the data that you want to be able to search efficiently. In the Re:amaze product, this means we built indices for any message or customer created within the inbox. For high volume inboxes, these indices needed to be rebuilt continually to allow the ability to search new data. Additionally, data within an inbox can be modified or deleted at any point, meaning another rebuild of the indices. Continual rebuilds, in addition to the volume of data being processed, made this feature a particularly difficult problem to solve.
Problems with the self-hosted search service
The self-hosted search service was accurate, fast, and provided a powerful set of features. We loved it! (No we didn't). As the product grew, so did the size of the indices, which complicated the maintenance of the search service. Some of these problems included:
- Lengthy time to index - The sheer number of messages to search was creating indices of over 100 GB in size. More data means more time to create the index. We were bordering on eight hours to build a single index. This time matters because if any error were to happen during the building process, we'd usually end up with a corrupted index and have to start over and rebuild the index from the start. We eventually set up alerts to ping our developers when it detected that indices were older than expected (which usually meant that indexing was failing for some reason).
- Lengthy backup and recovery processes - We had a daily cron job to back up (compressed) indices to S3 in case we ever needed to restore them. Because we were backing up very large files, these processes also were time consuming and error-prone. When we did need to use these backups, the restoration process would take some time to download these files and restart the search daemon.
- Inability to run on ephemeral nodes - Our self-hosted search service ran on non-ephemeral EC2 instances, which went against GoDaddy standards. Modifying that service to run on ephemeral nodes would have taken a significant investment of time. Large index files and a lengthy search daemon boot-up time made such a solution tricky.
- Inability to reindex all messages in a customer account - When a customer reports search issues, or any issue for that matter, we ideally want to immediately fix the issue for the customer and then debug how the user got into that state. For search, however, we could not selectively reindex a messages in a customer account to correct search queries if they were returning inaccurate results. This increased time to resolve customer issues.
We noticed that as the indices grew, crashes became more frequent. Eventually, the service would crash a couple times a month and the users weren't able to search their inbox for hours at a time. It took a lot of effort to bring back the search server and re-populate it with data that was lost during the crash. Team morale also took a hit whenever the service went down in the middle of the night.
Additionally, operating costs were high. All search queries were sent to a single large EC2 instance. This instance ran daily cron jobs to reindex entire indices and Sidekiq processes to index new data. The daily reindex read the entire database table that needed reindexing, which increased our database costs. For redundancy, we ran two additional search instances, which each ran similar reindexing routines. The hardware needed to run these instances along with the database load incurred was drilling a big hole in our budget. Since search was self-hosted, it was up to us to apply version upgrades and bug fixes on each of these instances, and we received monthly alerts that our service was not compliant with GoDaddy's ephemeral node requirements.
Possible replacements
We needed something that could replicate the same search features used in the inbox. As if that wasn't a tall order, we also wanted better operational features. Some of the features on our wishlist included:
- A fully-managed solution so we wouldn't have to spend time doing upgrades and security patches.
- Search that could handle our data volume (500 million records).
- Search speeds at least on par with the self-hosted search service.
- Technology that seamlessly fit our existing tech stack.
- Lower operational costs.
We narrowed down our potential replacements to two options: cloud-based Postgres and cloud-based Elasticsearch. We evaluated each option based on the features we wanted, the costs, and the learning curve.
Option #1: Cloud-based Postgres
We were already familiar with cloud-based AWS Aurora (Postgres) database servers. Tacking on full-text search to that shouldn't be too difficult. Learning curve would be short because of the team's familiarity with Postgres queries. Also, Postgres supports the search features that we wanted. But Postgres's full text search capabilities came short on a few things. The following table summarizes the pros and cons of cloud-based Postgres:
| Pros | Cons |
|---|---|
| 🟢 Fully-managed | 🟠 Expensive to operate |
| 🟢 Team familiarity | 🟠 Search features lack fine-grained control |
| 🟢 Short learning curve | 🟠 Search speed reduces when data increases |
| 🟢 Supports most of our search features |
The potential costs of running search on our cloud-based Postgres was looking very high. While it was easy to scale up the server to meet the additional compute needs of the search operations, it was also costly. These compute instances are memory-optimized instances built for handling huge relational data; not exactly the ideal configuration for CPU-intensive searches. And even if we had the additional server in place, search costs are tied to the volume of database reads. We anticipated this was going to cost us a lot, since search is widely used by thousands of our customers.
Also, the search features didn't provide fine-grained control. For example, we could do a phone number prefix search, but we couldn't restrict it to a minimum of three digits, or to adopt it for international phone numbers. The workaround for that was to add computed columns to the Postgres table, but that's not a flexible solution. For example, if we wanted to change the phone number prefix to a minimum four digits in the future, we'd have to repopulate the computed column. Definitely possible, but not as easy as turning a knob.
Option #2: Cloud-based Elasticsearch
The other option was Elasticsearch. We really liked this option. There would be a steeper learning curve, but it checked off many boxes we considered in the following evaluation:
| Pros | Cons |
|---|---|
| 🟢 Fully-managed | 🟠 Steeper learning curve |
| 🟢 Supports our search features | 🟠 No team familiarity |
| 🟢 Fine-grained control over search features | 🟠 Large initial time commitment |
| 🟢 Search speed unchanged when data increases | |
| 🟢 Lower operational cost |
These results aren't surprising as Elasticsearch is literally built to be a search service (search is in the name!). Elasticsearch also provided other benefits that we could see ourselves using down the line:
- We frequently run complex Postgres queries for populating sections of the application. These queries can take very long to execute so we could move that data into Elastic and reduce the load on the Postgres server.
- Elastic offers semantic search (or vector search) that we could possibly use for our AI and LLM tools.
- Adding search to other parts of the application would take very minimal work.
Implementation
With Elasticsearch ticking more boxes than Postgres, we had our winner. Now we'd have a much larger challenge: the implementation Elasticsearch. We identified the five main hurdles in implementing the solution:
- Adopting the search features
- Handling the data volume
- Keeping the data in sync
- Incorporating selective ingestion
- Making the switchover
Adopting the search features
Having made Elasticsearch our choice, we built a proof of concept (POC) to test out each of the search features we considered. The POC was a Ruby on Rails app connected to an Elastic cluster and layered with the elasticsearch-model library which is useful in performing various operations on data exchanges between Rails applications and Elastic. We populated the cluster with dummy auto-generated data. This approach allowed us to test and debug each of the search features independently. We ended up spending a lot of time tweaking the knobs to get the results just right, including:
- Using a combination of analyzers to split email addresses and match on partial words.
- Testing phone numbers in different formats (
+16260001111,16260001111,(626) 000-1111) resolved to the same record. - Using Elastic's built-in mechanism to return HTML representing the search phrase.
- Running the same query through Elasticsearch and the older search service to compare the results for accuracy.
Handling the data volume
So we got the accuracy and search features figured out. Then we moved on to operational questions:
- Can we ingest 500 million records within a reasonable amount of time?
- How much hardware (CPU, memory, and disk) is needed for the ingestion?
- Can we selectively reingest (or correct) a portion of the data?
We tried out different strategies to ingest the data. We used a snapshot of real production data (approximately 4 TB) for our testing, ensuring that the results would be similar to running it in production. Data in the database tables were portioned out in chunks to multiple workers. Each worker spun off more workers to read and write smaller chunks. The two bottlenecks were database reading speed and Elastic writing speed. We experimented with varying the size of the chunks, as well as varying the number of workers. We also monitored the CPU utilization during our tests. In the end, we came up with an optimal chunk size and number of workers for each end of the operations (reading vs. writing). The optimal configuration was as fast as our hardware allowed, but without over-burdening the CPU.
We played around with hardware changes as well. Usage of CPU-optimized Graviton nodes gave us an extra 25% boost in ingestion speed (the default was storage-optimized nodes). Not only that, but it also gave huge cost savings. If we had continued adopting the storage-optimized nodes, we would have had to add more nodes to achieve those CPU needs. That would have cost a lot more. In comparison with the hardware costs of the self-hosted search service, Elastic hardware costs were 60% less overall. These hardware optimizations in combination gave us a much larger cost savings than we had initially expected.
Keeping the data in sync
Having gotten all the data into Elastic servers, the next challenge was to keep data in sync. We have a very active user base and data gets added and updated every second. If we don't keep our app's database in sync with the Elastic server, our searches won't be accurate.
With the self-hosted search service, the syncing mechanism was controlled by the search service, and we didn't have much visibility into it. It frequently got out of sync so we had a periodic job that reingested all the data. And this was costing us a lot of money in read I/O costs.
For our Elasticsearch service, we wanted to:
- Have visibility and control over the syncing mechanism, possibly with some logging and monitoring.
- Quickly correct a specific index that went out of sync without needing to do a full reingest.
- Avoid running the periodic reingest job.
We set up callbacks every time data changed on a table. That was easy. Some of our search data came from association tables, so we set up callbacks to update data whenever the associated record changed. Then we had a few places where we update data in bulk, which would bypass the callbacks. By testing and trial and error, we found different spots in the application where a bulk update was happening, and we patched all the holes. Since the volume of data changes was constant and very high, we were careful not to fire callbacks on every single change. We are only searching on a handful of filters and text fields. So we cleaned that up, and reduced the number of callbacks to Elastic. Callback processing was also offloaded to async workers.
Then came handling conflicts. Since our callback processing was happening in async workers, we ran into the possiblity of two Elastic workers writing to the same record on the Elastic server. There was no way we could handle conflicts like this on an individual basis because of the high volume of data changes. Fortunately, Elastic provides in-built conflict resolution mechanisms. The UpdateByQuery Elastic API allows us to update specific rows based on a condition, but also we could specify what it should do in case of conflicts. It supported retries so most of the time Elastic was able to resolve it on its own on the second retry. But sometimes, the API would return failure due to unresolvable conflicts. In such cases, we built a fallback mechanism that would reingest that specific row of data with the latest data it found in the application's database. This was a game changer. 90% of the time, the UpdateByQuery retries took care of things. The remaining 10% was taken care of by the fallback mechanism.
The end result was a fully-synced symbiosis between the app's database, and the Elastic server. There was no need to run a daily cron job to keep the data in sync. In the months after we released, we've very rarely needed to do a full reingest. This saved us a ton on read I/O costs. In fact, 40% of our total cost savings came from not needing to do periodic reingestion.
Incorporating selective ingestion
Historically we saw that there were times where search was just out of date or inaccurate with what was stored on the database. Having a way to quickly correct the indices while we researched the source of the issue was important. The Elasticsearch Ruby module was useful here, as it provided functionality to granualarly update a single record out of millions if needed. We made tweaks to the ingestion process to optionally follow a custom condition, so that, for example, we could reingest only a specific index, or a specific customer's data. Having this ability gave us peace of mind.
Making the switchover
The final step was to incorporate all this work into our production app. A smooth switchover was necessary. We didn't want customers impacted when we swapped the self-hosted search service out. So we decided to populate and maintain (temporarily) both search services in-sync with the app. By doing it this way, we were able to slowly roll out the change to a handful of initial customers and quickly rollback if there were any reported issues.
Additionally, since both search services were active, we could compare results of the two to determine if search results were comparable. Any customer feedback on the new search was addressed immediately. Kibana logs and observability metrics helped with troubleshooting issues with indices, as well as to monitor the Elastic cluster.
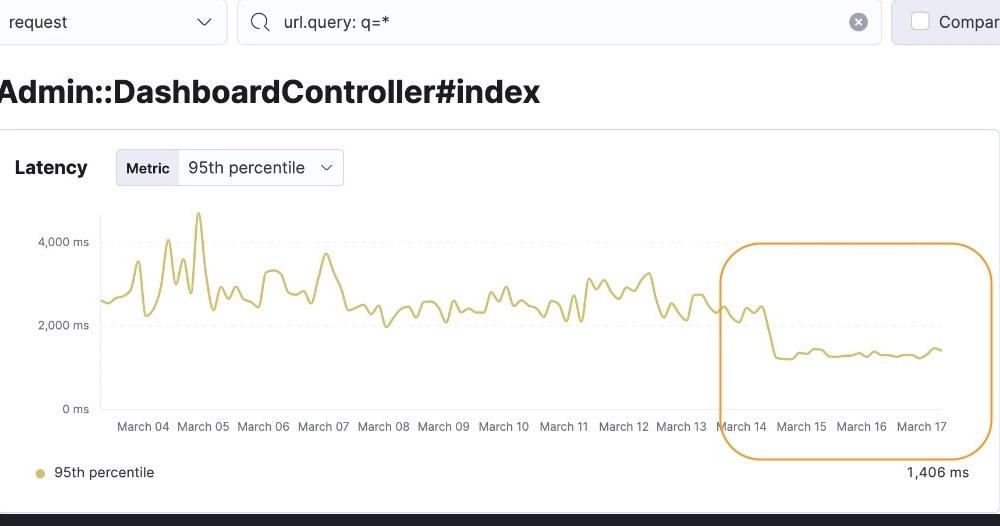
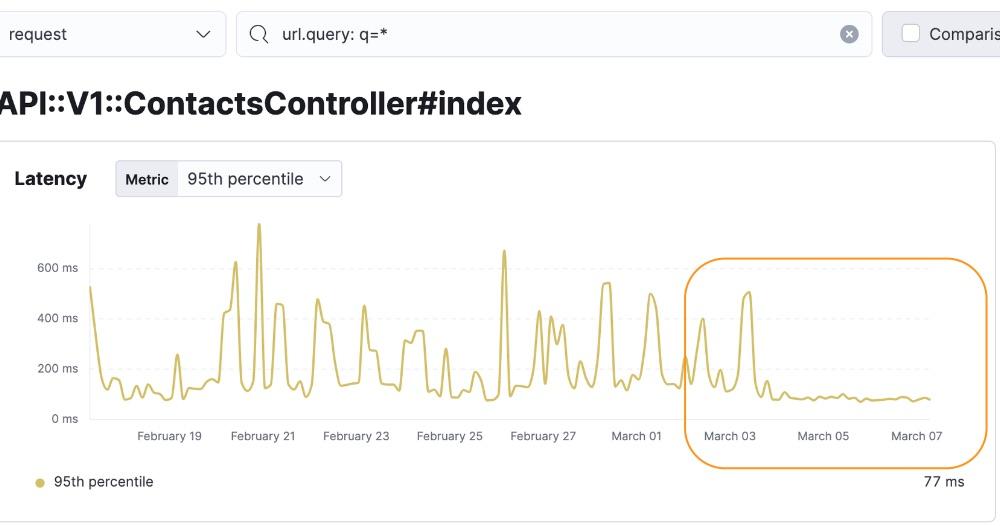
Eventually we did a full rollout and sent all search traffic to the new search cluster. After the full rollout, we found our search-enabled pages had ~25% lower latency overall as illustrated in the following charts:
Dashboard:
Contacts:
This latency reduction wasn't one of the goals we had started off with, so it was an unexpected surprise. Finally, after all customer reported issues were addressed and we were comfortably running on Elasticsearch, we decommissioned our self-hosted search instances.
Takeaways
We needed to improve on our self-hosted search service. Over the years it had become less dependable. So we identified the major issues (occasional crashes, high operating costs, long indexing time, lengthy recovery speeds). We chose cloud-based Elasticsearch as our replacement solution, and what we ended up with was:
- Uninterrupted search with 100% search uptime.
- Smooth switchover to new search service.
- Lower latency for searches results.
- $15,000/month in cost savings.
Not bad. Turned out better than our initial expectations!





