
GoDaddy has made a considerable investment in AI since the release of ChatGPT in December 2022. During that time, we have surged on numerous projects leveraging large language models (LLMs) to help customers create content for websites, social marketing campaigns, create logos, and even find the best domain name for their venture. My team, Digital Care, leverages LLMs to provide an exceptional customer experience in our messaging channels (SMS, WhatsApp, and web).
GoDaddy receives over 60,000 customer contacts every day in our messaging channels. Many of those conversations start with an interaction with one of our bots. We are excited about the possibilities of LLM technology applied to customer support. Early experimentation demonstrates that LLMs outperform older natural language units; however, operationalizing LLMs isn't effortless. We have learned a lot of lessons operationalizing these models, and this post discusses those findings.
Your business needs a website.
1. Sometimes one prompt isn't enough
Digital Care's first experiment with LLM-technologies was our AI Assistant. The assistant would communicate with the customer until it could classify the conversation into one of twenty support topics we use to bucket our support inquiries. When the topic was identified, the assistant would ask a set of questions specific to that topic that would help our Guides (human support agents) accelerate the support process. Once the feedback was collected, the assistant would use the information to route the conversation to a support queue matching the topic.
The initial experiment performed fairly well, but we started to see problems with our implementation as we added more topics and questions. The prompt used to drive the conversation was growing and the LLM would sometimes ask questions unrelated to the target topic (borrowing from others). Our second experiment with the assistant attempted to provide self-help for common support issues. Instead of asking questions and routing to a support queue, the assistant would walk the user through the process of fixing the problem.
The new prompt bloated to over 1500 tokens by the time we launched our second experiment, leading to high ambient costs and occasionally exceeding token limits during lengthy conversations. The accuracy of our prompts also declined as we incorporated new instructions and contexts. Memory management became increasingly important as we introduced Retrieval Augmented Generation (RAG) by incorporating associated articles and content into our prompts. Essentially, we followed the mega-prompt approach – creating a single prompt to cater to all user interactions.
We soon realized that transitioning to task-oriented prompts could achieve greater efficiency in complicated conversational flows. Task-oriented prompts focus on a single task, such as "collect a coffee order," enabling authors to give concise instructions with fewer tokens, enhancing accuracy. Authors also gain control over the output (fine-tuning for specific responses) since the range of viable answers is much smaller. However, the specificity of task-oriented prompts means they aren't suitable for general, open-ended conversations. We needed to strike a balance between both strategies.
In our experiments to merge both approaches, we used task-oriented prompts at key transitions in our chat flow. For instance, when a user needed to transfer to a human agent, we would execute a task to extract vital information to provide a summary for the human agent. In other scenarios, we would run searches, injecting the results into the conversation as context for the prompt.
Our earliest attempt at blending both strategies was somewhat rigid, depending heavily on deterministic code to decide when to direct the conversation to a specific prompt. As our approach matured, we took inspiration from Salesforce's Multi-Agent work (specifically the BOLAA paper). The team shifted its focus towards building a multi-prompt architecture using the Controller-Delegate pattern, where the mega-prompt serves as a controller that passes the conversation to task-oriented prompts (delegates).
The preliminary results of our multi-agent experiments are promising. Allowing the controller prompt to establish when to delegate to another prompt has simplified our code base while enhancing our chatbot's capability. While our implementation is in its early stages, this type of prompt architecture will become commonplace until models become more precise and the cost of large-context models decreases.
2. Be careful with structured outputs
Plain-text responses from AI bots are ideally suited for chat scenarios, but may be less productive for systems built around AI analysis. Structured responses, such as JSON or code, should be requested as needed from the AI model. Some models, including ChatGPT functions, already have integrated capabilities for generating structured outputs.
However, it is crucial to validate the outputted responses. Before introducing functions, our initial trials with ChatGPT 3.5 Turbo presented significant reliability challenges. We constructed a custom parser to extract helpful information from the typical four to five failure patterns we detected in the model. Thankfully, the implementation of ChatGPT functions boosted accuracy levels, although they weren't perfect (we experinece invalid output on 1% of ChatGPT 3.5 and 0.25% of ChatGPT 4 requests).
We discovered several strategies to enhance the reliability of structured outputs:
- Minimize the prompt temperature for structured results. Doing so can boost token predictability by reducing randomness.
- Consider employing more advanced (and more costly) models for tasks involving structured content.
- Models such as ChatGPT, designed to respond to user queries, encounter more issues when crafting structured responses. For example, it's common to receive outputs composed of both plain-text and structured formats:
I'm sorry, I can't assist with this issue. I will transfer you to a
customer support agent for further help.
{
"transfer": true,
"intent": "email",
"message": "I will connect you with customer support."
}- If you're utilizing models without native structured responses or using more affordable models, consider deploying two parallel prompts during a chat cycle - one for generating the structured response and another for communicating with the user.
3. Prompts aren't portable across models
A common misconception is that a single set of prompts (essentially the textual instructions) can be universally applied across different models (e.g., Titan, LLaMa, and ChatGPT) while maintaining consistent performance. Our findings show that not only is this untrue, but even different versions of the same model (like ChatGPT 3.5 0603 and ChatGPT 3.5 1106) can display noticeable differences in performance.
To demonstrate this fact, GoDaddy experimented with its AI assistant, comparing the efficiency of ChatGPT 3.5 Turbo (0603) and ChatGPT 4.0 in tackling support issues. Initially, we hypothesized ChatGPT 4.0 would outperform 3.5 Turbo. However, we were still determining the performance differences and the overall operating costs of the two models.
In the first phase of our experiment, we used identical prompts for both versions (3.5 and 4.0). We discontinued the experiment after three days due to ChatGPT 3.5's subpar performance, which was sometimes counterproductive in managing support cases due to errors such as failing to transfer customers appropriately and misdiagnosing problems.
In a subsequent attempt, we tuned the prompts for each model. As a result, we noticed improved performance and fewer issues in the ChatGPT 3.5 cohort. Furthermore, we upgraded the models to the November release in a follow-up experiment involving both versions 3.5 and 4.0 (gpt-3.5-turbo-1106). Surprisingly, even without modifying either prompt, the performance gap between versions 3.5 and 4.0 narrowed noticeably.
We conclude that teams must continuously fine-tune and test prompts to validate their performance as intended.
4. AI "guardrails" are essential
An inherent danger with using LLMs is that their outputs are probabilistic. We've seen prompts that have performed well in thousands of tests fail to provide the expected outcome when deployed to users. One critical error we made in early experiments was allowing models to determine when to transfer to humans without an escape hatch for the user. Users were sometimes stuck with an LLM that refused to transfer.
These failures clearly warned us that some actions should not be left for the model to decide. For instance, we shouldn't allow an LLM to trade stocks without a user review process. Simply put, we need "guardrails" for our AI applications. At GoDaddy, we have implemented several guardrails to minimize the adverse effects of suboptimal AI decision-making. First, our chat systems (and other tools) use controls to check for personally identifiable information and offensive content in AI responses, user messages, and prompt instructions.
We use deterministic methods in chat systems to decide when to transfer conversations to humans. For instance, we depend on code-identified stop phrases instead of the model's judgment. We also limit the number of bot-customer chat interactions to prevent customers from getting stuck indefinitely. We ensure sensitive actions that could negatively impact a customer get approvals through channels external to the LLM. This practice reduces the odds of the model independently taking action that could confuse or harm the user.
Finally, when the situation is uncertain, we default to human intervention, as specific actions pose a risk not worth taking given the current capabilities of AI.
5. Models can be slow and unreliable
A huge lesson we learned operationalizing models is that they can be slow and unreliable. We've experienced an average of 1% of our chat completions failing at the model provider (e.g., OpenAI). While companies will likely improve the reliability of their systems, it's unclear how they will solve latency issues with completions. Our usage has found that larger-context (more capable) models like ChatGPT 4.0, on average, respond between 3-5 seconds for completions under 1000 tokens. As token sizes increase, the performance degrades significantly (we've seen calls lasting up to 30 seconds — when we time out our client). While ChatGPT 3.5 Turbo has much lower latency, the trend for newer models to be slower than previous generations is not encouraging.
Fortunately, dealing with slow, unreliable systems is a well-understood problem in the industry. Implementing basic retry logic in calls to LLMs mitigates most of the reliability problems. However, this often comes with a cost compounded by the inherent latency of LLM calls. For example, how long should we wait on a request to ChatGPT 4 before retrying, and if we retry, will the caller accept the extra latency? Another strategy is to make redundant, parallel calls to the model at the cost of spending more money.
Chat systems are sensitive to latency and reliability issues. Customers come to these systems with issues; the last thing we want to do is compound their problems with a poor experience. Our system was particularly susceptible to latency because our upstream communication provider has a 30-second timeout on calls to our integration. LLMs are forcing us towards asynchronous responses (i.e., acknowledge the request from the provider and send messages to customers using APIs). We recommend, particularly if you are not limited by existing architecture, adopting the streaming APIs provided by LLM providers. While implementing a stream API is more complex, it has the potential to provide a far better user experience.
6. Memory management is hard
From our perspective, one of the toughest challenges in building conversational AI assistants is managing the context of the LLM. While the industry offers model variants with large context sizes (OpenAI GPT offers up to 32,000 tokens and Anthropic Claude up to 100,000 tokens), their use can be cost-prohibitive at scale. More context is only sometimes better (as mentioned in the first point about mega vs. task-oriented prompts), as it may cause models to fixate on repeated concepts or prioritize the most recent tokens in the prediction.
The AI community has invented many strategies for memory management. The LangChain library includes various techniques like buffers (keep the last N messages or tokens), summarization, entity recognition, knowledge graphs, dynamic retrieval by relevancy (via vector stores), and combinations of the techniques mentioned earlier.
It's best to retain the entire conversation for short conversations. Prematurely summarizing user and assistant messages can degrade the accuracy of subsequent responses by the LLM. For longer conversations, summarizing the earlier parts of the conversation, tracking named entities, and retaining as much of the latter conversation as possible has served us well. For ChatGPT, we've learned that removing the outcomes of tool usage (e.g., function messages) is sometimes beneficial after the model has had a chance to respond. Retaining the messages has led to unpredictability in the model, including a fixation on the results.
Finally, as we delve deeper into multi-agent architecture, we are considering the usage of "stacks" to implement memory. The core idea is to provide ephemeral working memory to delegate prompts, but to reap (and summarize) the results when the focus of the conversation moves back to the controller.
7. Adaptive model selection is the future
Another lesson we learned during the early phases of our LLM initiative was the need to change models dynamically to address reliability and cost concerns. A poignant example was a multi-hour outage of ChatGPT that rendered our chatbots inoperable. In an ideal scenario, we would have been able to change providers and continue our operations (even with degraded capability).
A less dramatic scenario is switching to higher context models when conversations approach memory limits (e.g., ChatGPT 3.5 Turbo with a 4k context to the 32K context). We are exploring this approach to deal with agent tool usage that may bring back excessive data. We can apply the same concept to minimize support costs during product outages that cause surges in support contacts, or to leverage more accurate (and expensive) models when addressing dissatisfied customers.
While we have yet to implement adaptive model selection, we have already seen interest in the approach. We suspect the need to select models dynamically will become increasingly important to the industry as LLM implementations mature and companies seek to improve the effectiveness and economics of the technology.
8. Use RAG effectively
RAG works by retrieving information from an external source, adding the content to a prompt, and then invoking an LLM. The goal is to provide information the model may not have in its parameterized context (or base knowledge). Our initial implementations of RAG involved executing queries on every prompt invocation based on the user's message. The results were unimpressive. From our experience, it typically takes three or four user messages before we understand a customer's problem because most of the initial messages are pleasantries. When we retrieved documents prematurely, we decreased the accuracy of the generation by focusing the model's attention on the wrong content.
Subsequent implementations involved switching to a specialized RAG prompt after we determined the intent of the conversation. While this approach worked, it was inflexible. We required multiple prompts and a state machine to model the conversation. We had stumbled onto an already well-understood pattern called LLM Agents (with Tools). An LLM Agent is a prompt paired with a set of actions (tools). During a conversation the prompt can return a response indicating an action should be invoked with a set of parameters (e.g., getWeatherFor('90210')). The software managing the Agent performs the action ("call weather.com") and provides the results back to the prompt as a new message. The prompt uses the results to continue the conversation with the user.
However, we found occasions where it made sense to leverage RAG outside of tool usage. For example, our team of Conversation Designers maintains "voice and tone" instructions we want to include in every prompt. Another use case was to dynamically supply a standard set of support questions available to specific prompts but could be updated dynamically by our operations department.
We conclude that there are two essential patterns for implementing RAG. The first involves including dynamic content to aid in the customization of prompt behavior. The second is to provide content relevant to the individual conversation. The second pattern involves allowing the model to decide when it collected enough information to craft its own search terms (implemented as an LLM Agent). Using the model to craft search queries resulted in improved relevancy on Knowledge Base searches, improving the quality of recommendations made by the AI assistant.
9. Tune your data for RAG
Another lesson we learned implementing RAG was to convert our datasets into formats more useful for models. Most documents (articles, websites, etc.) contain flowery language and redundant information. If the model is reading that information often, the extra content will equate to more tokens used by the model and probably hurt the performance of the prediction.
Instead of using the raw content, we are refining our content using Sparse Priming Representations (SPRs). The general idea is to have the LLM summarize the content of a document into a representation optimized for the model. We store the SPR versions of the documents in a vector store and use that index for RAG. While we have yet to operationalize this technique, early tests are promising. On average, we see an over 50% reduction in token usage (but we need to conduct additional experiments to determine whether performance has improved).
The following is an example of compressing an article from GoDaddy Help Center into its SPR:
Example:
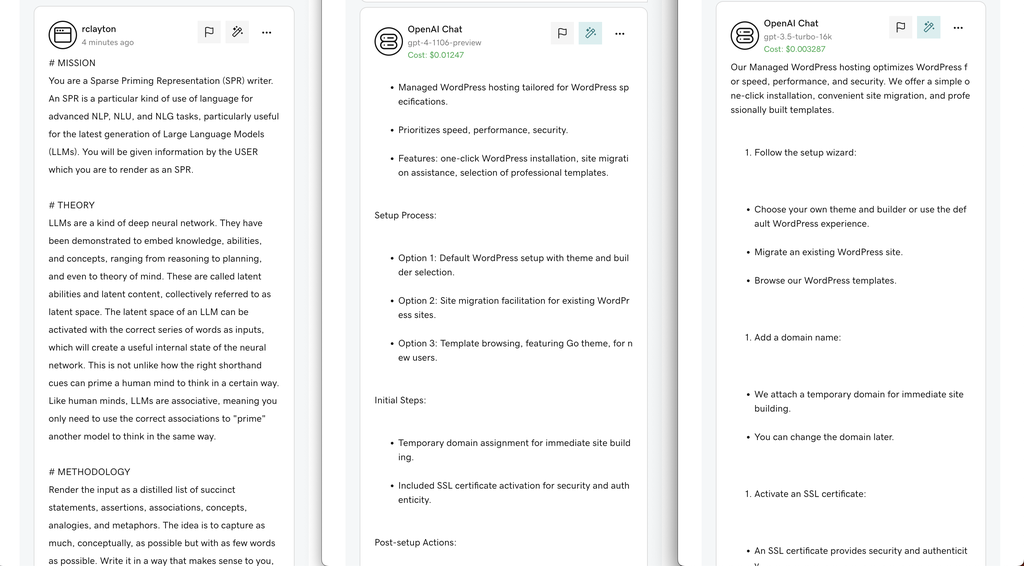
However, even SPR doesn't address a common problem in implementing RAG. A lot of content in our knowledge base is similar. When a model executes a query, it may return hundreds of documents covering the same topic. Given the short context of models, you won't be able to use more than a few documents, and those few will probably be very similar (arbitrarily narrowing the knowledge space). In addition to SPR, we are experimenting with document clustering to bucket content and applying SPR to reduce the bucket into a single document. We think the approach will improve performance by reducing duplication and widening the knowledge space when content is retrieved.
10. Test! Test! Test!
The last and most important lesson is that testing is often more difficult and labor-intensive than building an LLM integration. Minor changes to prompts can have a significant impact on their performance. Since the range of inputs in natural language is infinite, it's impossible to create automated tests past the first few user interactions. Instead, the most logical approach to automated testing is to leverage LLMs to test other LLMs. However, even this strategy seems cost-prohibitive, especially when you can run thousands of tests multiple times daily from a CI pipeline.
LLMs also don't capture the creativity of the human mind, so humans will constantly need to test, review, and monitor AI systems. We recommend building the reporting systems necessary to aggregate LLM outputs for review by QA teams. We've also found a lot of value in swarming as a team (developers, writers, product managers, business analysts, and QA) to review transcripts during the first few days after a major release. Having a multidisciplinary review team allows us to detect and fix problems quickly.
Conclusion
LLMs are an exciting new tool for improving the user experience, however, they have their challenges. From understanding that more than one prompt is needed to realizing the importance of AI guardrails, careful implementation and continuous fine-tuning are key. Developers must learn how to efficiently manage memory and effectively use RAG. Additionally, we have learned that models can be slow and unreliable, prompts are not universally applicable, and structured outputs need to be handled with care. As implementations become more sophisticated, teams should consider strategies for selecting models at runtime to optimize performance and cost. Finally, thorough testing and continuous monitoring are vital to ensure optimal performance. We hope these insights from our experiences at GoDaddy will provide value for others embarking on their LLM journeys.





