In mid-2025, I was spending as much time correcting AI output as I saved generating it. So I started experimenting with treating AI agents as development colleagues rather than code-generation utilities. Instead of asking for snippets, I began delegating entire tasks — from understanding requirements to submitting a pull request. Individual tasks didn't necessarily get faster, but I could run multiple agent sessions in parallel — effectively working on several tasks simultaneously instead of sequentially. That shift was noticeable enough that I started sharing the approach across GoDaddy's entire developer community.
I started with GitHub Copilot, Cursor, and Claude Code, and have since settled primarily on Claude Code and Codex CLI. What I found is that the real leap happens when you stop treating AI as a tool and start treating it as a colleague. But getting there requires a deliberate approach, not just better prompts. This blog post talks about what agentic development actually means, why the transition is harder than expected, and a phased approach to get there.
What agentic development actually means
Think of AI adoption as a spectrum with four stages. The following list and chart outline these stages.
- Autocomplete — AI suggests code completions as you type
- Chat assistant — you ask questions and get code snippets back
- Task executor — you delegate small, focused tasks to an agent, steering each step with hands-on prompting
- Agent-as-colleague — AI drives entire workflows end-to-end while you guide and review
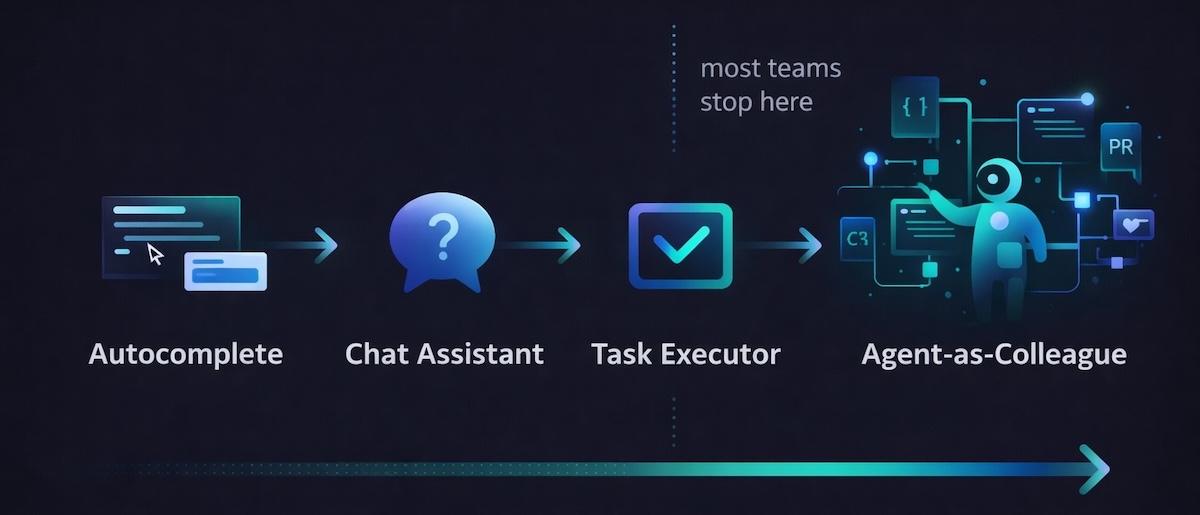
Most teams plateau at stage two or three, which is unfortunate because stage four is really different from the first three stages. In stage four, instead of the engineer being the primary driver, the agent drives entire tasks end-to-end — reading the codebase, planning an implementation, writing code, running tests, iterating on failures, and submitting a pull request — with the engineer reviewing and guiding the process.
This is not "AI writes everything." The engineer's judgment, design sense, and domain expertise become more important, not less. You're making higher-level decisions more frequently. There's a key behavioral shift in AI-assisted mode versus agentic mode. In AI-assisted mode, you fix the agent's output. In agentic mode, you coach the agent to fix its own output.
Why the transition is harder than you think
Adopting agentic development isn't a switch you flip. The following friction points often tend to slow teams down:
- Mindset friction. Engineers instinctively want to jump in and fix code the moment something looks wrong. Agentic development requires letting the agent iterate, which feels slower at first. It takes discipline to describe what's wrong rather than just editing the file yourself. The turning point for me was realizing that agents respond more like human colleagues than computers. When I stopped telling the agent what to change ("use a map instead of a list here") and started explaining why something needed to change ("this function is slow because it does linear lookups on every request"), the agent consistently came up with better solutions — sometimes approaches I hadn't even considered.
- Infrastructure gaps. Most codebases aren't ready. Without comprehensive test coverage, agents have no feedback loop to self-verify their work. Documentation written for humans skimming context gets misinterpreted by agents that read everything literally.
- Code review overload. Agent-generated code arrives in volume. Traditional line-by-line review doesn't scale when the agent produces dozens of files in a session.
- The adjustment period. Expect reduced productivity in the first couple weeks as engineers learn new workflows. Communicating this upfront prevents people from abandoning the approach before they see the gains.
A phased approach to adoption
Don't go fully agentic overnight. The teams I've seen succeed follow a deliberate progression: build the foundation, expand agent autonomy, then optimize the workflow. The following sections descibe this progression.
Phase 1 — Build the foundation
The first thing you should do is invest in feedback loops. This is the single highest-ROI infrastructure investment. Agents need ways to verify their own work. Test suites are the obvious one — I assigned an agent a refactoring task in a well-tested module, and it made its changes, ran the tests, saw two failures, diagnosed the root cause, and fixed them without my intervention.
But feedback loops go beyond tests. For a UI task, I gave the agent access to Puppeteer MCP tool that could take screenshots of the running application. The agent implemented the feature, took a screenshot, noticed the layout didn't match the requirements, and iterated on the styling until it looked right — all on its own. The more ways an agent can see the results of its work, the less hand-holding it needs. If your test suite is sparse or flaky, start there. Then look for other ways to give your agents eyes on their output.
After you're confident your feedback loops provide solid coverage, create agent-optimized documentation. Restructure key docs — project memory files, architecture decision records, coding conventions — so agents can consume them effectively. Write as if you're onboarding a new colleague who's technically skilled but has zero context on your systems. Be explicit about conventions that human engineers absorb from working on the team. Agents can only see what's in the repository — tribal knowledge that lives in people's heads needs to live in files instead.
Now that you've got a solid foundation, start with bounded tasks — bug fixes, test generation, migration scripts — tasks with clear inputs and verifiable outputs. This lets engineers learn agent strengths and failure modes without high stakes.
Phase 2 — Expand agent autonomy
The most important shift in this phase is learning to coach, not fix. The first time I watched an agent struggle through three wrong approaches before landing on the right one, every instinct told me to take over. I didn't — and the agent's final solution was better than what I would have written.
When the agent produces wrong output, resist the urge to edit directly. Describe what's wrong and let the agent iterate. Ask it to self-evaluate its approach. Capture recurring correction patterns as rules for future sessions — this creates a compounding improvement cycle where the agent makes the same mistake less and less.
After you're comfortable coaching, start assigning multi-step tasks. Graduate from single tasks to full workflows — design, implement, test, refactor. Give the agent a feature description and let it plan the implementation rather than dictating every step.
When agents handle full tasks reliably, run parallel sessions on different tasks simultaneously, each on its own branch. This is where the productivity gains really start to compound.
One morning, I kicked off three agent sessions over breakfast: one implementing a new API endpoint, one adding integration tests for an existing service, and one migrating a configuration file format. By the time I joined my daily standup, all three had pull requests ready for review. None of the individual tasks finished faster than if I'd done them myself — but doing three at once turned a full day's work into a couple of hours.
Phase 3 — Optimize the workflow
Start by rethinking code review. Use agent-assisted review as the first pass, catching style issues, test gaps, and common mistakes automatically. Focus human review on architecture decisions and business logic. For well-tested, low-risk changes that pass agent review and CI (continuous integration), consider skipping human review entirely — the automated checks may be sufficient.
As your team builds experience, share knowledge actively. Create channels for engineers to share patterns, effective strategies, and lessons learned. The techniques evolve quickly as models improve. What worked last month might have a better approach today.
Finally, right-size models to tasks. Not every task needs the most capable model. Match model capability to task complexity — use faster, cheaper models for straightforward tasks and reserve the most powerful models for complex reasoning. Costs can range from $20–100 per engineer per month depending on usage patterns, and right-sizing keeps that manageable as adoption scales.
What I learned
After several months of this approach, a few lessons stand out.
Infrastructure beats prompts. The biggest productivity gains came from infrastructure investments — tests and documentation — not from writing better prompts. In my experience, teams that invested in a solid test suite before expanding agent scope progressed faster than teams that tried to skip that step.
The coach mindset compounds. Engineers who embraced the "coach" mindset adapted faster than those who resisted letting go of direct editing. The instinct to grab the keyboard is strong, but the compounding returns from teaching the agent pay off within weeks.
Timelines vary. The transition isn't one-size-fits-all. Different teams and codebases need different timelines. A greenfield project with good test coverage might reach phase three in a month. A legacy codebase with minimal tests might spend two months on phase one.
The role shifts upward. Most importantly, the engineer's role shifts upward: more time on architecture, design, and product thinking; less time on implementation mechanics. This is an elevation of the role, not a replacement.
Moving forward
The leap from AI-assisted to fully agentic development isn't about AI getting smarter — it's about teams building the infrastructure, mindset, and approach to let agents work at their full potential. Organizations that invest in these foundations now will compound their advantage as models continue to improve.
If you're still in the autocomplete stage, start small. Pick one well-tested area of your codebase, try coaching instead of fixing, and see what happens. The phased approach gives you a way to build confidence incrementally without betting everything on a new workflow overnight.
Looking ahead, the next frontier is team-scale agentic development — where multiple engineers coordinate agents across an entire project, with agents handing off context to each other and collaborating on interdependent tasks. As model capabilities improve and context windows grow, the bottleneck will shift from what agents can do individually to how well teams orchestrate them. The organizations building that muscle now will be the ones ready to take advantage.