
A Quick Start Guide to Frontend Caching
🏎️ In the race to send the last bits needed to view a web page, we need to position ourselves to be as close to the finish line (browser) as possible! 🏁
The primary goal related to setting up a caching strategy on your client side web application is to ensure the browser fetches the latest version of a respective file only if required.
Let’s work through different caching scenarios as we build a web app from the ground up. In the last section, we provide an easy framework for you to derive an optimal caching strategy for any application!
This tutorial is primarily for learning purposes - providing fundamental building blocks of an optimal caching strategy. It provides a guided method to help anyone take the first steps towards either setting up or modifying an application’s caching strategy based on cache control headers specifically. Advanced topics such as service workers, CDNs, etc. are out of scope.
The Pet Web App
Imagine we have a simple Pet Web App that shows an image of a dog and cat.
To start off, we assume file versioning is not set up for any part of our project. Any modifications will overwrite the exact file. As we visit the next steps, we setup versioning, and then finally we add server side rendering. We’ll discuss the important caching policies each step might require for best performance.
First, here’s the project resource tree for our Pet Web App:
Pet Web App
│
├── main.js
├── style.css
│
├── index.html
│
├── images
│ ├── dog.jpg
│ └── cat.jpg
│
└── healthcheck.htmlindex.html- webpage primary HTML file. It will reference our code and image resources.main.js,style.css- Javascript/CSSdog.png,cat.jpg- Image fileshealthcheck.html- simple file with with the stringOK. Used by healthcheck services to ensure our project is running. You can visit this file by going to the following url:https://example-domain.com/healthcheck.html
The following image shows a graph of each html file and the resource(s) they reference:
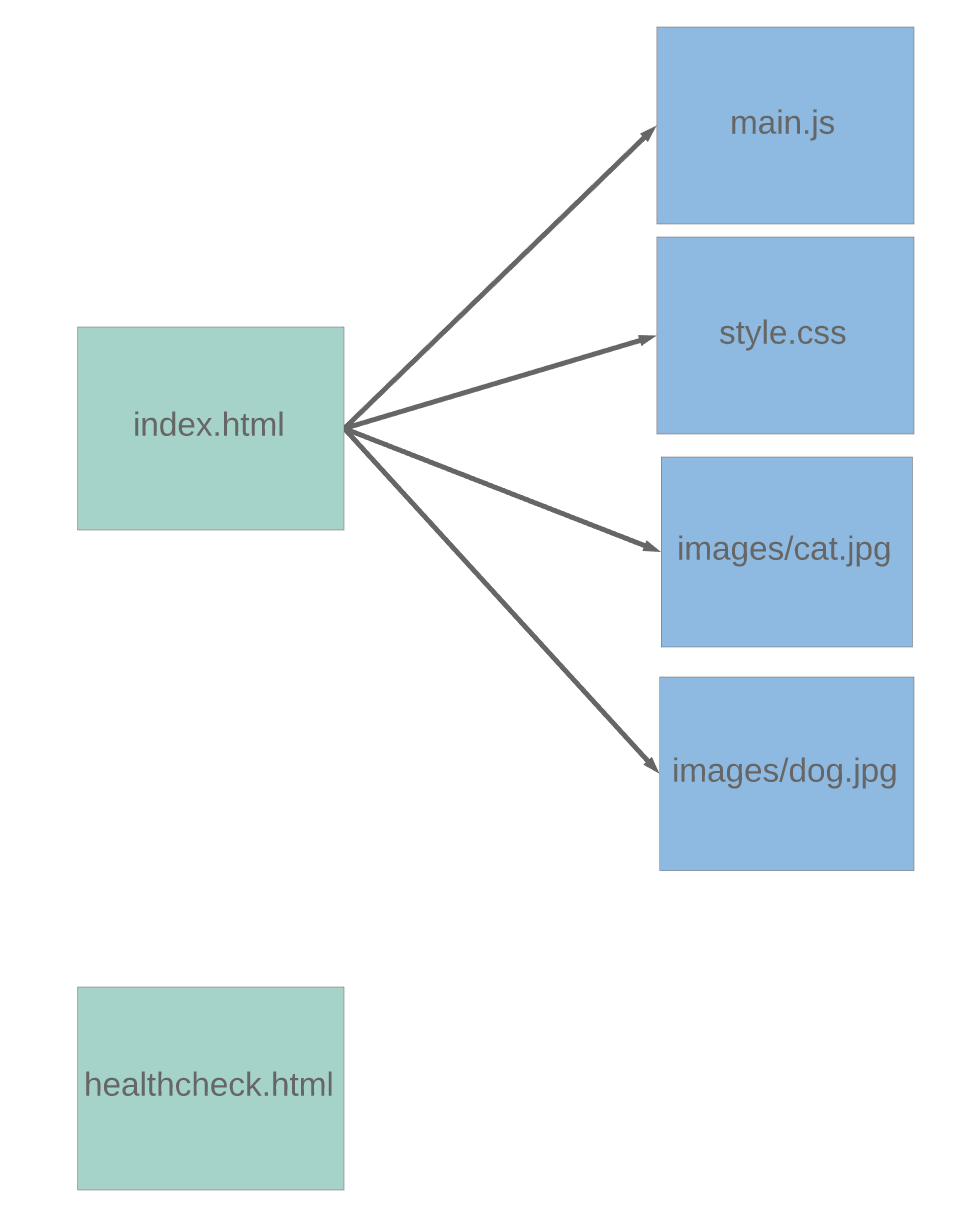
Now, each file part from our resource map has certain characteristics about its content.
We’ll focus on the following characteristics: Mutable and Immutable.
The type of content of each file being served is important to understand, as it allows us to think about the optimal caching behavior.
Mutable Content
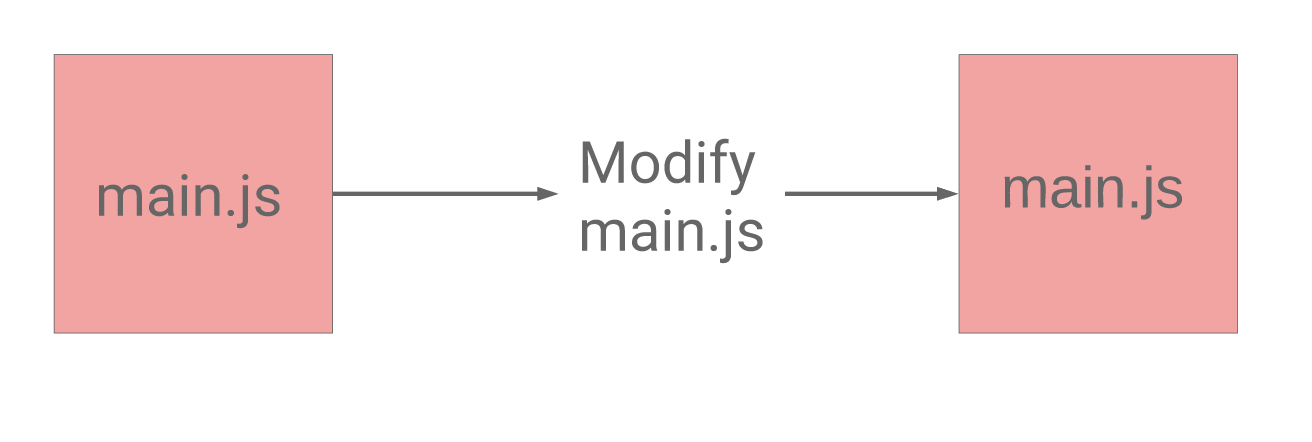
- If a file is mutable, then changes to it overwrite the file itself.
- Ideally, we always want users to have the latest contents from this file in a cache performant manner.
Immutable Content
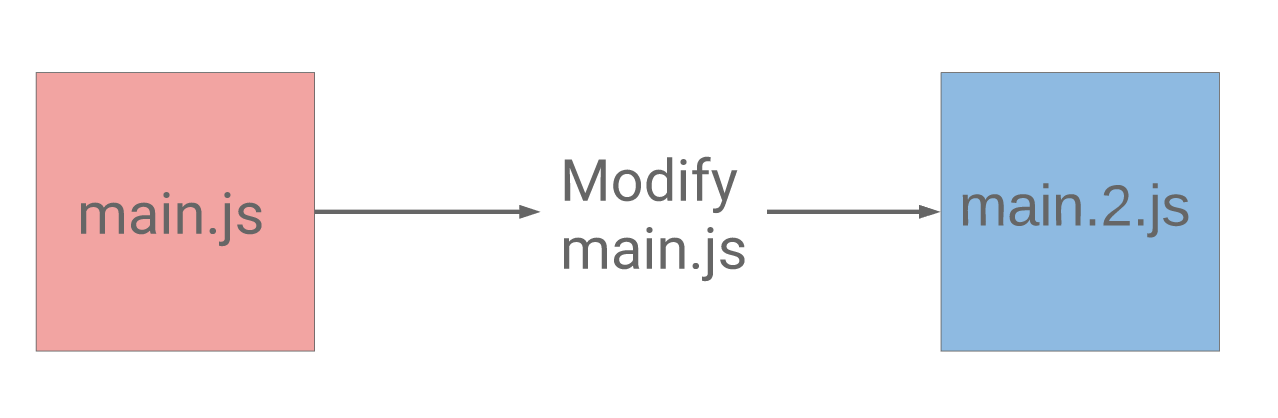
- If a file is immutable, then changes to it create a new file with a new name and do not modify the existing file. For example, (
main-v1.js,main-v2.js) - Ideally, we want users to download each respective version once, then never have to download it again.
Before we can discuss the optimal caching strategy for our project, we’ll map which files in the project resource tree are immutable and which are mutable:
index.html- mutable content: we might make changes for SEO or add different HTML elements to the file for various features. We can’t create an
index-v2.htmlsince browsers will always requestindex.htmlby default.
- mutable content: we might make changes for SEO or add different HTML elements to the file for various features. We can’t create an
main.js,style.css- Javascript/CSS- mutable content: these files will be modified as we make changes to our code for new features.
dog.png,cat.jpg- Image files- immutable content: we will not change these images.
healthcheck.html- immutable content. This file is special. It will always contain the text “OK”. We need to ensure clients will never cache this page. If it were cached, then clients would not contact the server and would not know if our server was capable of serving files.
After mapping out the each resource’s mutability or immutability, we can now choose a caching strategy and server configuration.
Caching Strategy
index.htmlCache-Control:no-cache- Server configuration:
ETags - Why: since the
index.htmlresource serves mutable content, any changes need to be reflected back to clients as soon as possible. However we don’t want clients to download this resource again if nothing was changed. This is where the cache control headerno-cachecomes in.no-cachedoes not mean don’t cache. It means ask the server if new content is available, and if so, download it. Otherwise, use what you have cached.Here’s a snippet from MDN which states what no-cache means: “Forces caches to submit the request to the origin server for validation before releasing a cached copy.”.Howeverno-cacheby itself won’t do much for us unless we define how the server will validate the cached resource. By setting upEtagsupport on the server, it can now validate the resources cached by the browser. Etags are opaque identifiers and typically implemented through checksums computed on the content of a file. AnETagvalue is then sent in each response. Browsers can validate their cached resource by asking the server if the current Etag for the file they have cached is still valid.
Side Note: If your server configuration does not allow for ETags, then you should switch to having browsers never cache the
index.htmlfile. This can be done by leveraging theno-storecache control directive instead ofno-cache.
The following diagram shows the flow between the browser and server for the scenario where the resource has not changed.
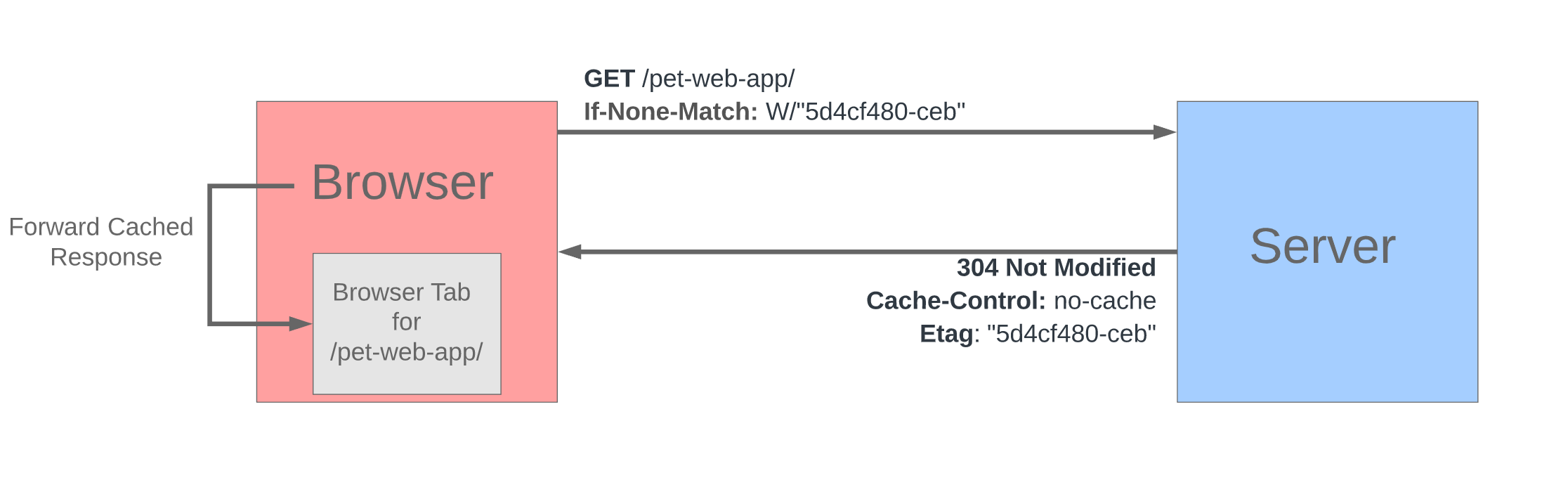
On the other hand, if the file has newer content, the following flow between the browser and server occurs.
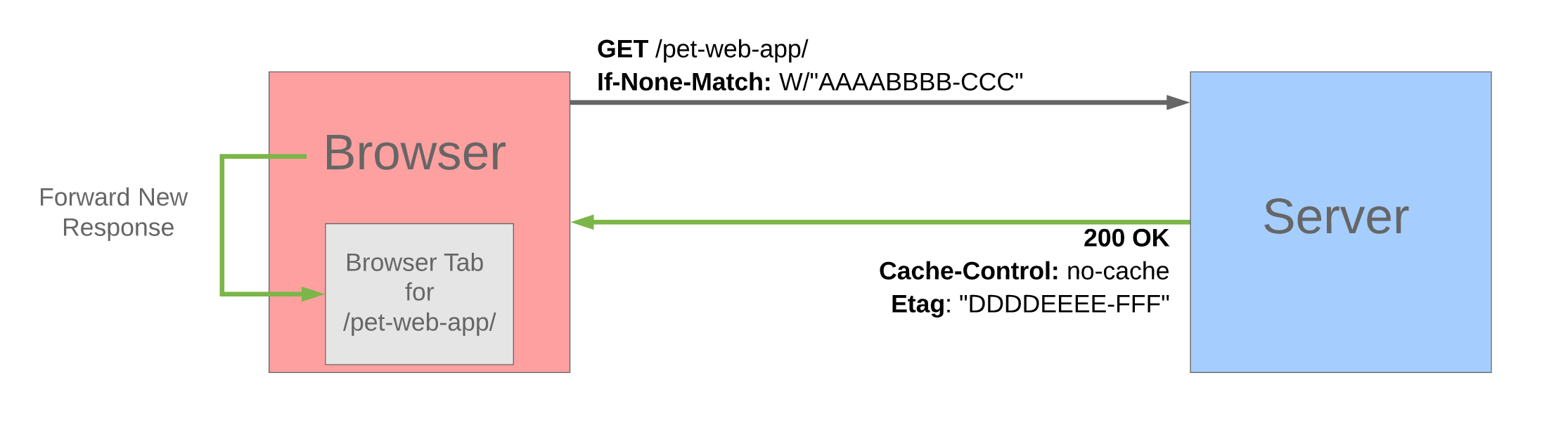
main.js,style.css- Javascript/CSSCache-Control: no-cache- Server configuration:
ETagsupport for cache validation - Why: Currently we’re not versioning these Javascript and CSS files, so when we make modifications, they overwrite the same files being served (i.e. they are mutable). Hence we need the same policy used for
index.html.
dog.png,cat.jpg- Image filesCache-Control = max-age: 31536000- Why: Our dog and cat pictures will never change (i.e. they are immutable), so we want the client to only download the file once and cache it for as long as possible.
Side Note: The HTTP 1.1 Specification states: “To mark a response as ‘never expires’, an origin server sends an Expires date approximately one year from the time the response is sent. HTTP/1.1 servers SHOULD NOT send Expires dates more than one year in the future.” Hence, the recommended
max-agevalue for a resource which never expires is 1 year. By settingmax-age: 31536000, we’re telling the client to cache it for up to 31536000 seconds, which is 1 year from the time of the request.
healthcheck.htmlCache-Control = no-store- Why: our
healthcheck.htmlneeds to be read as accurately as possible. Anyone or any service can check this page to detect whether the application is down. Hence, it should never be cached. Theno-storedirective tells the client to never store any response for this page in its cache, meaning the client will have to request a new copy for every request.
The following diagram shows the browser and server flow for the no-store scenario.
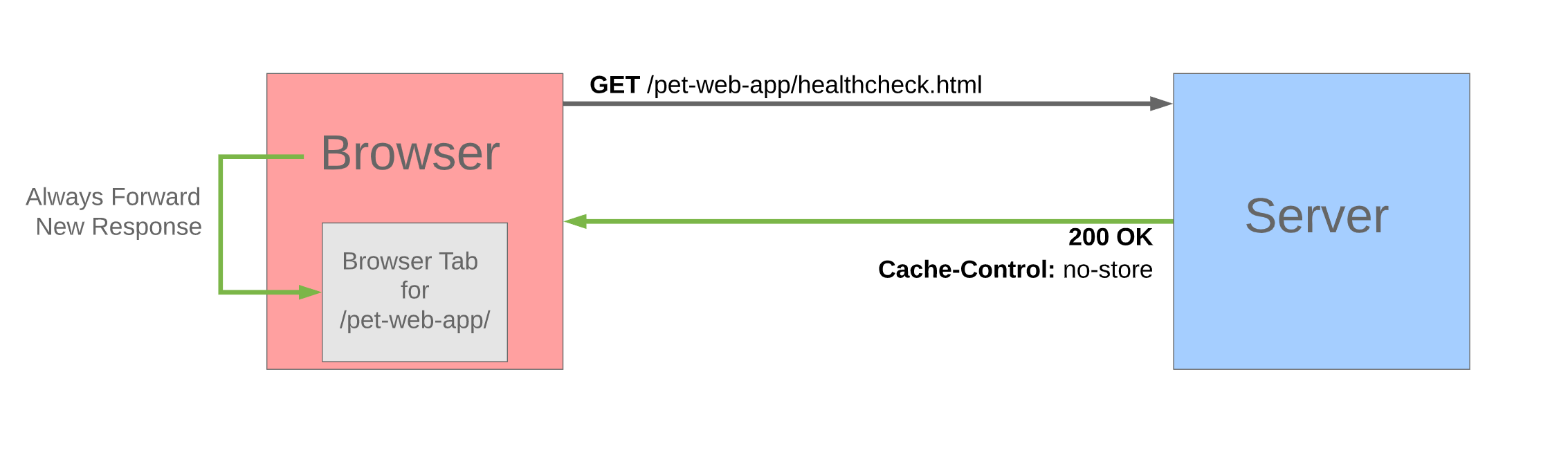
The Pet Web App project currently is a very basic application without versioning for our source code files. Yet, we do have an optimal caching policy which prevents unnecessary downloads of the project resources by the browser.
However, we can do better. We can set up versioning for our source code files such that the client will never have to ask the server to validate the currently cached copy of the resource. It will always use what it has cached. For this, let’s head to the next section.
Versioning For Our Resources
Let’s map out how we’ll leverage versioning for each resource to improve our caching strategy.
index.html- We can’t version this file since clients will always ask for
index.htmlby default, notindex-v2.html.
- We can’t version this file since clients will always ask for
main.js,style.css- We can version these files by including the version information in the file names, e.g.
main.[hash-of-contents].jsormain.[version].js. Including version information in the file names allows the browser to aggressively cache the files. If we make updates to these files, the names will change, and in turn ourindex.htmlfile must be updated, either through a bundler or task runner, to point to these newly generated files. The next time the browser requestsindex.html, the response will contain the new versions of these resources.
- We can version these files by including the version information in the file names, e.g.
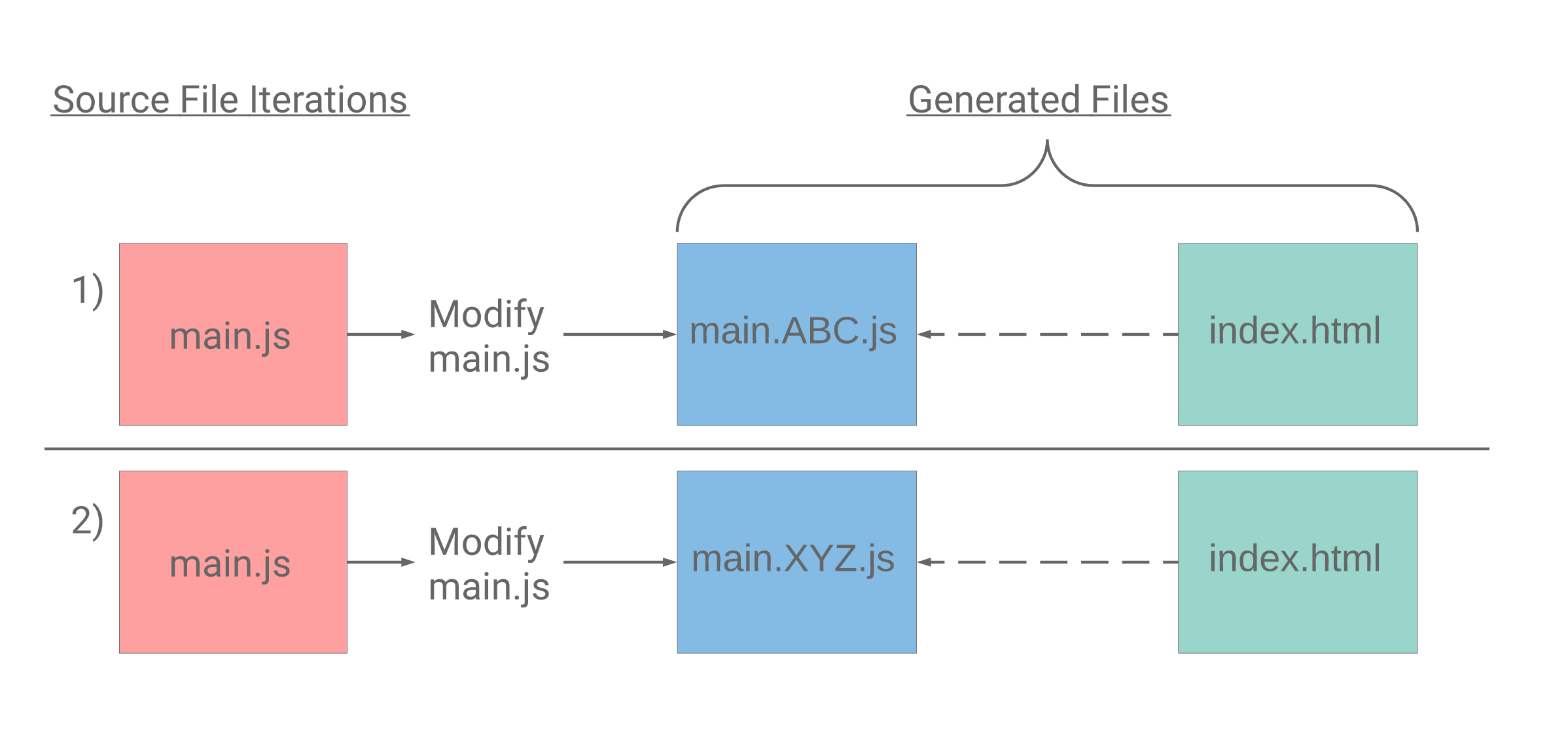
The following diagram depicts how index.html should be updated to always point to the latest generated main.[contenthash].js file. The same flow should occur for the style.css file.
dog.png,cat.jpg- In our example, we won’t be versioning these files, but you can version them by either putting the version information in the file name or placing them in a different folder, like
/v2.
- In our example, we won’t be versioning these files, but you can version them by either putting the version information in the file name or placing them in a different folder, like
healthcheck.html- Versioning is not applicable, since no client should cache this resource
Side Note: If you use a bundler like webpack you can have it generate files with content hashes included in their names.
With our versioning criteria set, we see that the mutability of our Javascript and CSS files has now changed.
main.[contenthash].js,style.[contenthash].css- Javascript/CSS- immutable content: as we make changes to our application source code files, the generated file names will include a distinct content hash or version information. The content in any previously generated javascript or css file will not be overridden. A completely new file is created.
Finally we can update the caching policy based off the new content charactistic of our Javascript and CSS files.
Caching Strategy Update
main.[contenthash].js,style.[contenthash].css- Javascript/CSSCache-Control = max-age: 31536000- server config:
ETagsupport - Why: We want clients to download these resources once, and then aggresively cache them. Each change made in the source code results in a newly generated Javascript or CSS file. Thus, our
index.htmlfile should be updated to point to the new resources. Once theindex.htmlfile is updated, all clients would now only download our new Javascript and CSS files.
Big picture
The following diagram depicts how index.html will refer to the newer resources after changes:
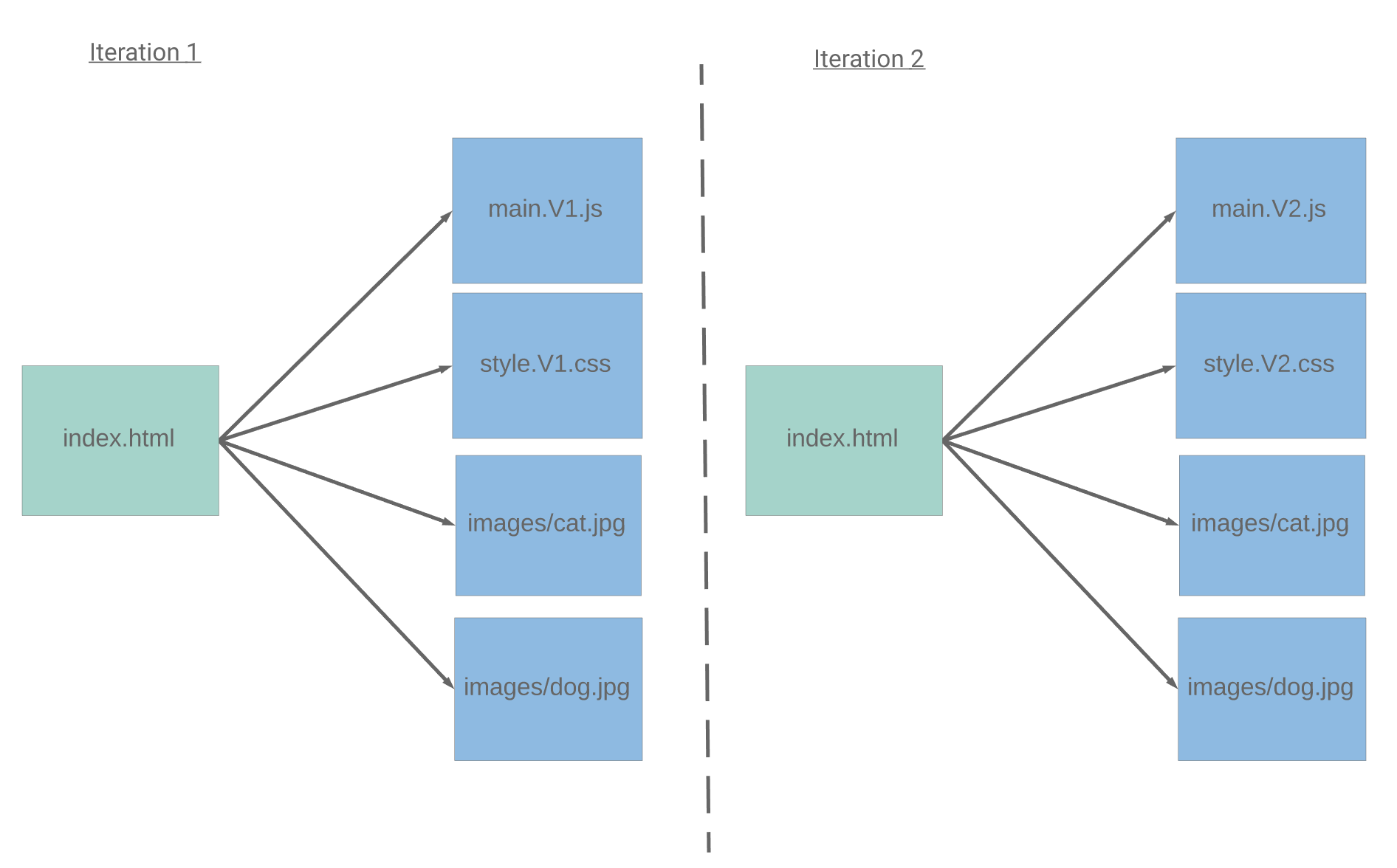
Server Side Rendering
Let’s say we now want to optimize our site for performance by leveraging server-side rendering (SSR). We want to pre-render some of our content. As a result, we won’t have an index.html file anymore. We’ll have an index API route, e.g. /, which responds to requests. Everything else in the project remains the same.
Let’s look at the content characterisitic of our index API route:
/- mutable content: Just like
index.html, the content of our index route will change over time.
- mutable content: Just like
Based off the content characteristic of the resource, we can generate an optimal caching policy:
/Cache-Control: no-cache- server configuration:
ETagsupport for cache validation - Why: We need clients to always fetch the latest version of this route’s content since it will change over time. However we also don’t want clients to download this resource again if nothing was changed. This is where the cache control header
no-cachecomes in.no-cachedoes not mean don’t cache. It means always ask the server first if new content is available, and if so, download it and use the latest content.
But wait! I already set Cache-Control headers for my resources, how should I update them?
If you already set Cache-Control headers for your resources and want to update them, then you have a few options, depending on the content characteristic of the resource. Regardless of content characteristic, your first step will be updating the Cache-Control headers. Your next move depends on whether the resource is mutable or immutable:
Mutable
In the places where this resource is referenced, append a dynamic query string parameter to the resource’s url. The browser will be forced to fetch the latest version of the resource, and in turn, it will also get the latest value of the respective Cache-Control header. Example:
Before: <script type="text/javascript" src="my-file.js"></script>
After: <script type="text/javascript" src="my-file.js?version=2"></script>
If you don’t want to append a query parameter, another option would be to place the resource under a new versioned folder, e.g. /v2/my-file.js.
A Cache-Control header on index.html presents a unique problem. It’s a mutable resource that can’t be versioned, so how can we propagate the new header? If your web application is behind a CDN or a hosting provider then you can leverage the provider’s capabilities for flushing the cache, if that feature is supported. However, in the worst case, you can try the following if you have analytics for your web application: - Update the cache control header and add a tracking code to index.html. - Analyze how many users are hitting the new index.html vs the older index.html. - This provides an overview of how your new content is being propagated across all your users. - From this, you can set a threshold of how many users should be visiting the newer index.html over a span of N days. - If the threshold is reached, then you’re set. If not, and the Cache-Control header is set to a long period of time, then you’re pretty much at the mercy of the browsers. Hence, the Cache-Control header for index.html is very important to set correctly from the start!
Immutable
If the resource is immutable, then no changes should be needed. As discussed in the immutable resource portion of this post, edits to the source files generate new corresponding build files with unique identifiers. In this case, the html files referencing the resource would be updated to request the new version, resulting in browsers downloading the new files along with the newly set Cache-Control headers, as long as the html file itself had appropriate Cache-Control headers.
Easy 3 Step Process Toward An Optimal Caching Strategy
Notice that there is a pattern emerging for developing an optimal caching strategy. Here’s how you can compute an optimal caching strategy for a web application:
- First create a project resource map.
- For example, check your
index.htmland look for all the individual resources your page will load. Also, don’t forget about any dynamically loaded resource (e.g, lazy loaded javascript, css, images, etc). Build a project resource map from this analysis.
- Determine the content characteristic of each resource in the project resource map. Is the resource immutable or mutable ? If the resource is mutable, can it benefit from being converted to an immutable resource with a proper versioning scheme?
- Based off the content characteristic of each resource you can now create an optimal caching strategy.
- If the content is immutable then cache it for as long as possible. For example:
Cache-Control = max-age: 31536000. - If the content is mutable then we would like browsers to cache the file until we change it. For example:
Cache-Control = no-cachewith etags enabled on the server.
Conclusion
We hope this post helps you create an optimal caching strategy for your application. We focused primarily on the Cache-Control header, but there are other ways to improve browser caching and the delivery speed of your web application, such as leveraging service workers or a Content Delivery Network (CDN). Good luck and happy caching! 🏎️
Attributions
- Cover Photo by Kolleen Gladden on Unsplash
- Dog by Template from the Noun Project
- Cat by Denis Sazhin from the Noun Project




