
You put some files on a server and users grab them; that’s hosting, right? Sure, if you’re stuck in the 90’s. While there have been significant innovations in this space, it’s been largely uneventful in the last 10 years. As is evident from ismyhostfastyet.com, a compelling open source project that visualizes anonymous real-user monitoring data reported by Google Chrome, we’ve considerable opportunity for innovation. Before diving into the technical details, let’s get the results out of the way…
Results
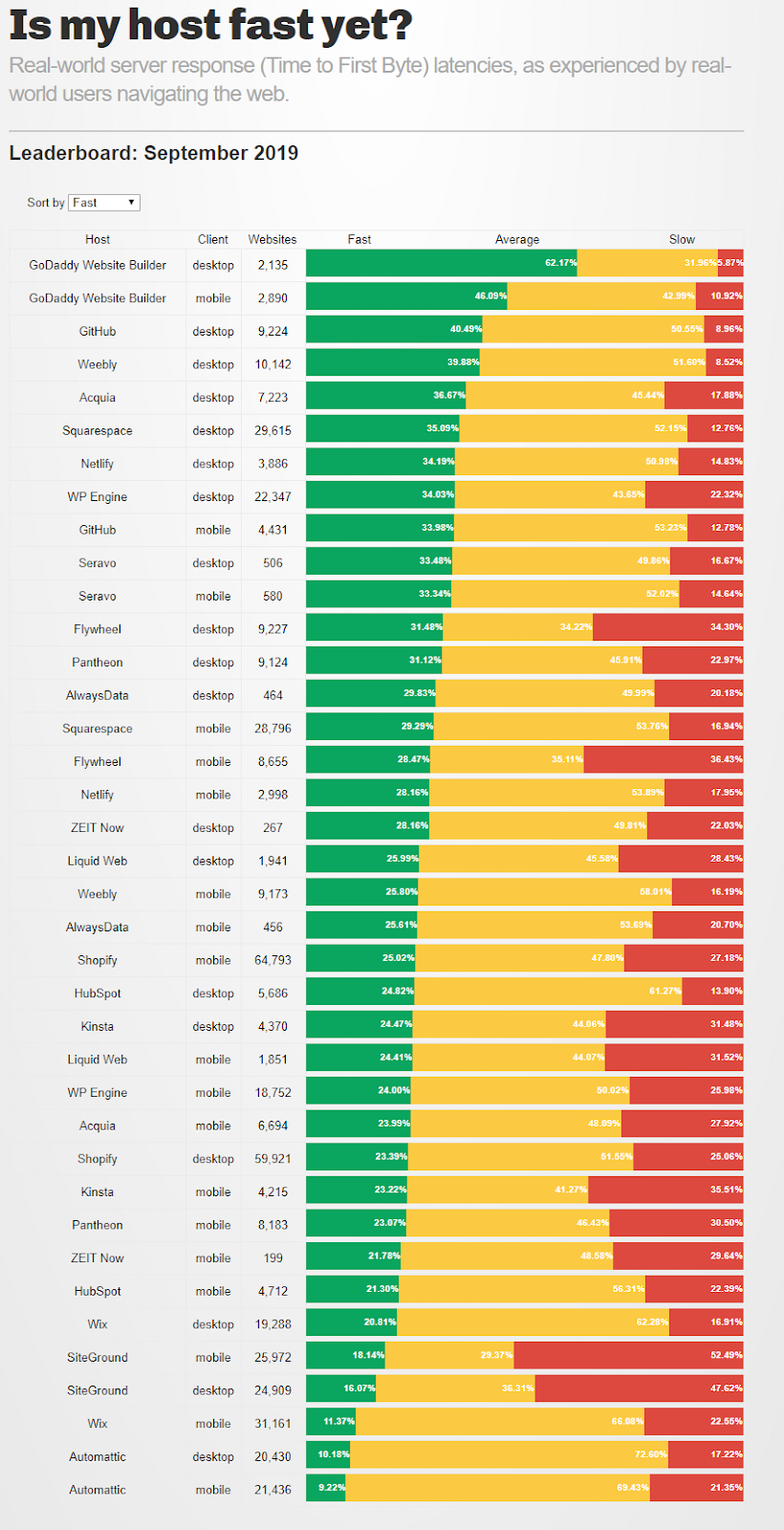
Not bad eh? Apparently not all hosts are equal, with large variances in time to first byte between the slowest and the fastest. The delta is further demonstrated by noticing that mobile clients visiting GoDaddy Website Builder experience less latency than desktop clients visiting all other hosting platforms on the chart.
How fast is fast?
Imagine you had a theme park with the fastest rollercoasters in the world, but the only way to get there was for vehicles to travel on dirt roads. The key idea behind this report is that regardless of how optimized your web application may be, if the host serving the application isn’t fast, you cannot provide a great experience.
This report qualifies less than 200ms TTFB (Time To First Byte) as fast, 200-1000ms TTFB as average, and greater than 1000ms TTFB as slow. Pretty generous if you ask me, considering TTFB is the point in time before a browser can begin to render and download dependencies of a page, 1000ms (1 second) is simply an unreasonable amount of time to wait for your host to respond. There have been numerous studies that have proven every 100ms has measurable impact, 500ms has significant impact, and 1000ms or more has a significant detriment to traffic to your website.
Google has shown that having a page load take 3s vs 1s increased bounce rate by 32%. If you want any chance of landing in the 1-2s sweet spot for page loads, your TTFB should ideally land in the 200-300ms range to give a well optimized page ample time to do everything it needs.
What is this wizardry?
No tricks, just physics. Approximately every 100km (~62mi) from data centers adds 1ms of latency to client requests (RTT). Based on the worst case distance (half the circumference of earth), round trips can theoretically reach upwards of 200ms over fiber. This is before factoring in indirect routes, two to three round trips to establish connections (predominantly secured), and last-mile latencies from Internet Service Providers. If you’re serving all users from a single data center, parts of the world are likely to see roughly an overhead of 600-800ms simply due to distance. Add in the overhead of host response, and this can quickly reach 1000ms and beyond before your users begin to see something render. If you’re still not sold on how critical TTFB is between your host and your client, let’s look at this problem through another lens. Client latencies have a far greater (and linear) impact compared to that of bandwidth. This means optimizing response times between client and host often will have a greater impact than reducing the size of your applications – though naturally you should do both. Why then are we so obsessed with “fat pipes”?
Custom stack
Surely you didn’t think physics was the only hand at play here? After all, your host is ultimately responsible for establishing connections (typically secured) and serving up the requested page.

When we designed the hosting stack for GoDaddy Website Builder over 6 years ago, there were numerous off the shelf technologies we could have leveraged to get the job done, and done well. That was the easy and most obvious path. Instead we approached the problem as an opportunity to cater the solution specifically to the needs of users spanning the globe, and ultimately to provide a world class platform from which our customers could be proud to host their ideas and accelerate their ventures. Running a hosting platform on Node.js, which is JavaScript running in Google’s V8 engine, was fraught with skepticism. After all, fast JavaScript is an oxymoron, right?
Runtime language matters, especially for CPU bound operations. But when it comes to I/O bound tasks, which is often the case with hosting, your runtime plays an important but less significant role. Instead of chaining together general purpose technologies - that range from load balancers, to web servers, and caching - we approached the problem with a single cohesive stack that has full control over the quality experience throughout the process required to serve a customers request. This approach has allowed us to emphasize customer experience over throughput by performing all necessary computations in parallel.
Benefits of our custom stack:
- Custom certificate management via SNI allows us to prime the pipe
- Easily integrate with any storage medium, finely tuned to handle large and elastic volumes of concurrency
- Custom render stack designed for our product, no general purpose bells and whistles needed
- Custom tuning of static vs dynamic content so we’re only performing CPU bound tasks only if required
- Custom caching strategies allow us to tune behaviors based on our actual customer flows instead of general purpose rules designed to win benchmark wars
- Never feature limited as any feature added to the product can receive custom support by its hosting counterpart
Mission accomplished?
Not hardly. Despite our wins in this space, there are significant opportunities that remain. We’re eager to talk about the innovations in our next chapter of hosting, but we’re not there so hang tight. In the meantime, check out our Site Speed article for another perspective on website performance.





