
Finding the right data is hard.
Sound familiar? This was a quote from our 2018 Analytic Data Survey. It showed that only 41% of respondants trusted and understood the data they consumed. At that time, data was directly replicated into our on-prem Hadoop lake from production databases. Then, thousands of long-running undocumented data processes ran on these often misunderstood, constantly changing raw data tables. The raw data tables were tightly coupled to the source systems and had no ownership. The result was an unorganized and incoherent mess of 166,685 tables across 979 databases. Our lake had become a swamp and something had to change. Our solution was to organize the data lake into distinct layers with clear delineations of ownership, business logic, and usage; in other words, a layered architecture.
GoDaddy’s layered architecture
As an almost 20 year old company in 2019, we needed to make some changes to become the data-driven company we aspired to be. Implementing a layered architecture data model would be the first major step. The concept of layered architecture isn’t a unique concept in the world of data, but how each company implements their architecture can vary. Databricks describes a medallion architechture consisting of three layers. We implemented a four layer model that best suited our data and needs.
The following sections define each layer and their functions in our layered architecture.
Source
The source is where the raw data originates from. It can be a SQL database (like MySQL or MSSQL), a NoSQL database (like DynamoDB), or files stored in a SFTP server. Data within the source is often non-replayable (no versioning is maintained) because it is an operational system that is mainly concerned with the current state.
Raw layer
The Raw layer is the first layer of the data lake and it ingests data, as-is from the source system. It serves as private replayable storage for the data producer. For example, if the data is ingressed on a daily cadence then they can look back at two previous partitions to know the state of the data two days ago. This is extremely helpful with operation tasks (like backfilling and debugging cleansing logic).
Clean layer
The Clean layer stores filtered, schematized, relationalized, standardized, compacted, compressed, and cleaned data for easier integration with other data sources. This layer provides an abstraction from the source system schema so it can evolve without breaking downstream consumers.
Enterprise layer
The Enterprise layer integrates the data from the Clean layer to build conformed facts and dimensions. It abstracts consumers from the entire notion of source systems and frames everything into an Enterprise context. It contains data from multiple systems updated with governed enterprise business logic (like rules to classify customers) to reduce duplicative processing and ensure consistency in definitions. This serves of the foundational layer for most downstream processing.
Analytical layer
The Analytical Layer is the final layer of the data lake and consolidates the conformed data from the Enterprise layer into easy to use cubes. It usually combines several enterprise tables used for business analysis and data science. Data in the Analytical layer are usually in highly denormalized form, contain aggregated data, and may contain some non-governed domain-specific logic.
Trade-offs between layers
As we go deeper in the data lake there are less joins, making the ease-of-use higher. However, the trade-off is higher latency and higher risk of outages due to the high number of dependencies. The following diagram illustrates these trade-offs for data consumers as they go deeper into the data lake.
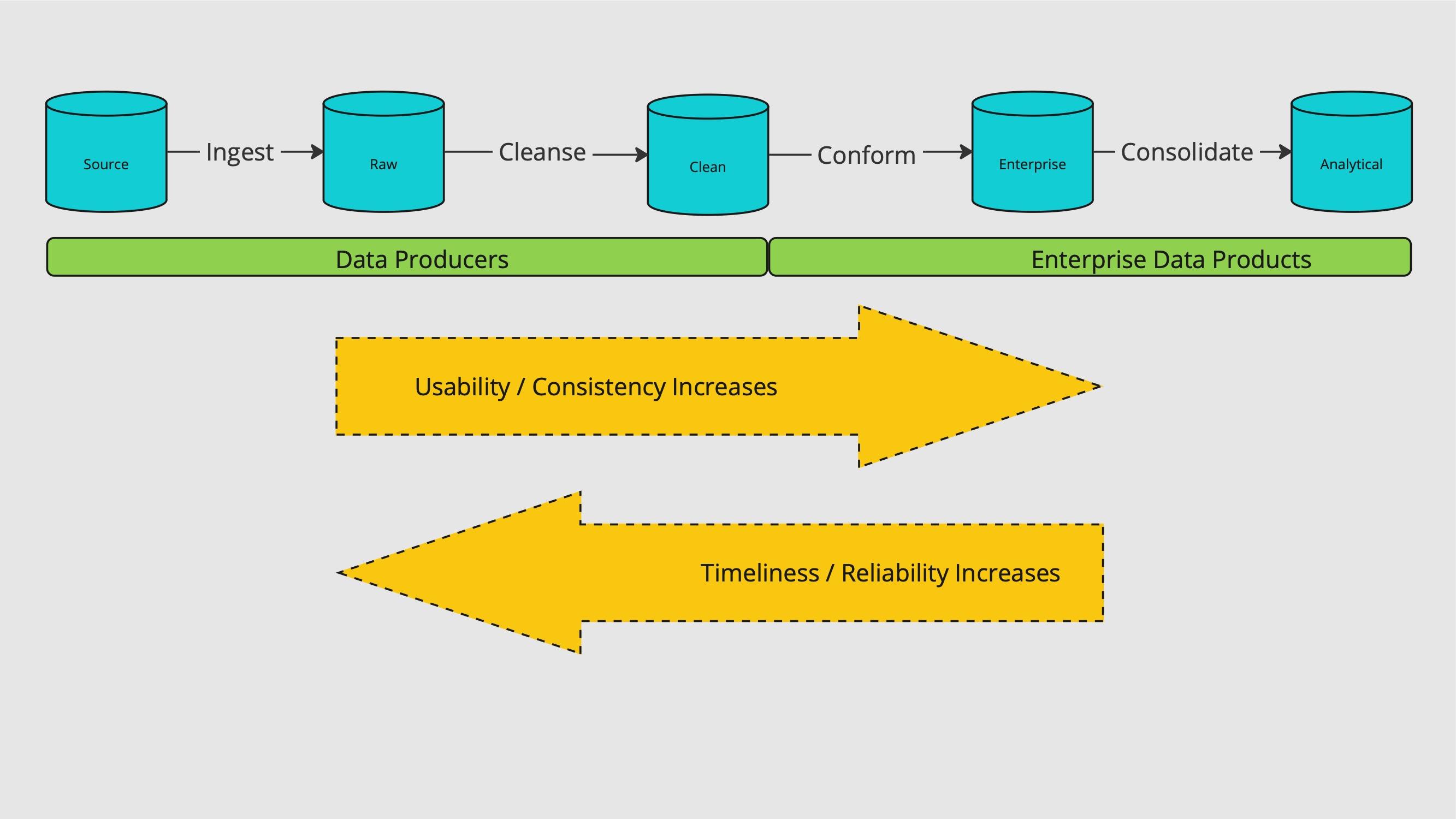
Ultimately, clearly defining the data in each layer helps consumers determine the best place to source data for their use case. For some use cases, reducing latency is of the upmost importance so consumers may opt to consume from Clean and Enterprise layers. This means their jobs will likely have to perform many joins, process lots of rows, and implement complex logic. In other cases, consumers have a high tolerance for delays and opt to use more curated data sets to keep their processes simple, light-weight, and fast.
Differentiation between the Clean and Enterprise layers
The Clean and Enterprise layers can cause some confusion because they have some similarities with each other. The following chart provides a comparison between the two layers.
| Aspect | Clean Layer | Enterprise Layer |
|---|---|---|
| Naming | Applies naming standards to raw names . For example, conversationTs => conversation_mst_ts. | Applies naming standards to conform our Enterprise logical data model. For example, conversation_mst_ts => care_chat_mst_ts. |
| Data Types | Applies data type standards to raw definitions and can add a partition column. For example: order_ts string => order_utc_ts timestamp + order_utc_date date order_amt bigint => order_local_amt decimal (18,2) | Applies enterprise data types for consistent use. For example: order_utc_ts timestamp => order_mst_ts timestamp + order_mst_date date order_local_amt decimal (18,2) => order_usd_amt decimal (18,2) |
| Business Logic | Performs corrections in technical debt. For example, fills in missing values, removes duplicates, and breaks apart overloaded columns. | Performs business logic that is approved by Data Governance, has not changed for 30+ days, and is used by 2+ business lines. For example, trxn_gcr_amt * trxn_exchange_rate = constant_currency_gcr_usd_amt |
| Data Sources | Uses Raw data and Clean lookup tables from the same source system. | Uses Clean data and Enterprise lookups from the same Data Domain (like Subscriptions). |
| Data Model Scope | Uses the Source system. | Uses the Enterprise. |
Execution plan
In the past, data producers had minimal responsibilites for their data. They never really had to think about data before and now they were forced to consider things that previously went unadressed. With a layered architecture in place, we now needed much more from our data producers. There were obvious benefits to this model for data consumers, but what about data producers?
Well data producers saw benefits too, along with the obvious benefits to data consumers. The new layered architecture provided data producers with:
- An abstraction layer - With an abstraction layer, we were able to remove tight coupling. Producers no longer had to worry about breaking downstream systems every time they made a change. This was great news for one team that ran into this issue so many times that they used to create a new table for every feature. The abstraction layer reduced the amount of work this team needed to do for each feature release and the likelihood of causing errors downstream.
- Easy to use tools - We invested heavily in our internal tooling that removed much of the complexity and repetitive tasks to produce data. These tools helped to allow data producers to focus on their services, applications, and platforms instead of having to focus on producing data.
- Better data - Data consumers were not the only ones to benefit from better data. Data producers reciveved more reliable, timely, and performant analytics on their products and services which helped them build better products.
Conclusion
Change is not always easy, especially when dealing with data, but the adoption has been rapid. We have now 108 clean databases owned by 97 source data producers, and we greatly reduced our overall table count from 160,000+ tables to 2,600 (-98.4%) due to eliminating widespread data duplication with the Enterprise Layer.
Now, 79% of our data consumers trust and understand the data; almost double what we saw at the start (41%). Finding the right data doesn’t have to be so hard anymore…
Cover Photo Attribution: Photo generated using DALL-E2 through GoCaaS. GoCaaS is GoDaddy’s own internal centralized platform that provides generative AI for GoDaddy employees and products to consume.





