
In March of 2018, GoDaddy and AWS announced a multi-year transition plan to migrate the majority of GoDaddy’s infrastructure to AWS. The Application Services team was formed and tasked with helping the rest of the company move workloads to AWS. As with any plan of that scale, we knew there would be several concerns we’d have to address. How would we ensure that business and customer data remains secure? How would developer workflows and processes have to adapt to a cloud environment? How should we adopt and apply architectural best practices? We knew that allowing development teams to quickly provision entire environments would be a boon for productivity, but those teams would be operating outside of the traditional “guard rails” of on-premise infrastructure. Teams could no longer assume that “someone else” was managing firewalls, ACLs, patching cycles, and other traditional operations tasks.
Trust, but verify
As development teams onboarded to AWS, the Application Services team recognized that teams would need to iterate on design approaches taken. It didn’t make sense for us to try to anticipate which services would be used or exactly how those services would be configured. What we did know was that we had to transfer knowledge of security best practices to the development teams, and make sure that development teams didn’t accidentally leave vulnerable configurations in place. We’ve all heard enough stories of customer data leaked because someone left an S3 bucket exposed!
Additionally, each development team would have multiple AWS accounts (one for each deployment stage), so any solution used would have to support hundreds (and eventually thousands) of AWS accounts.
We then undertook a search of tools (both open source and commercial) that we could leverage to scan accounts for any security-related concerns. We needed a tool that could scale to many accounts, evaluate an ever-expanding list of configuration items, and run within the VPC of the target account so that we could run network-based tests against them.
CirrusScan
While we found some good tools available, none met all of the criteria we had outlined. Once we had ruled out all of the available options, we had to settle on some key design considerations for our custom built solution:
Container based, so that we can run it inside the target account’s VPC, and
perform arbitrary tasks that aren’t tied to a particular languageServerless, so that we don’t have to pay for unused resources in between
scanning tasks, and that could scale easily
We named the resulting framework “CirrusScan”, and crafted CloudFormation templates that provide the following architecture:
CirrusScan Architecture:
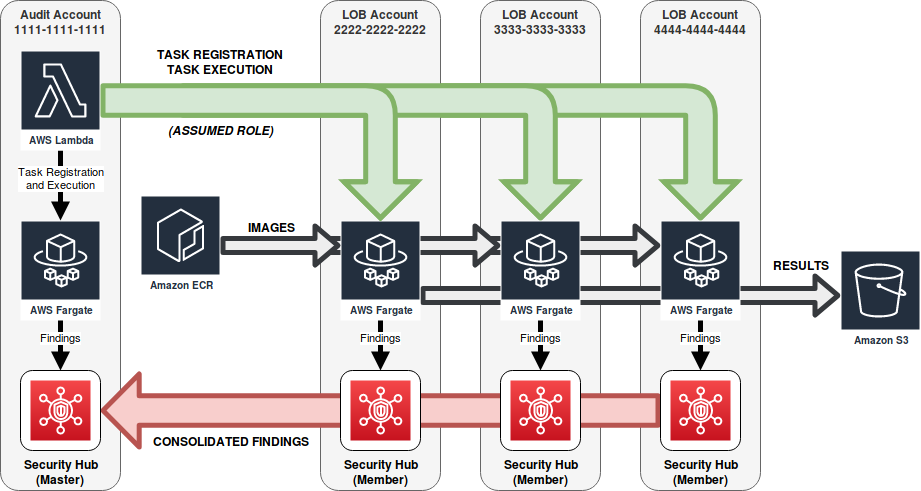
With this approach, we have a global Audit account that schedules checks to be run in each LOB (line of business) account. The global Audit account registers ECS task definitions in each development team’s LOB accounts for any security checks that should be performed. We use Fargate so that we can avoid having any running worker nodes in between security check executions. This also minimizes the footprint that CirrusScan requires in each of the accounts that we want to verify.
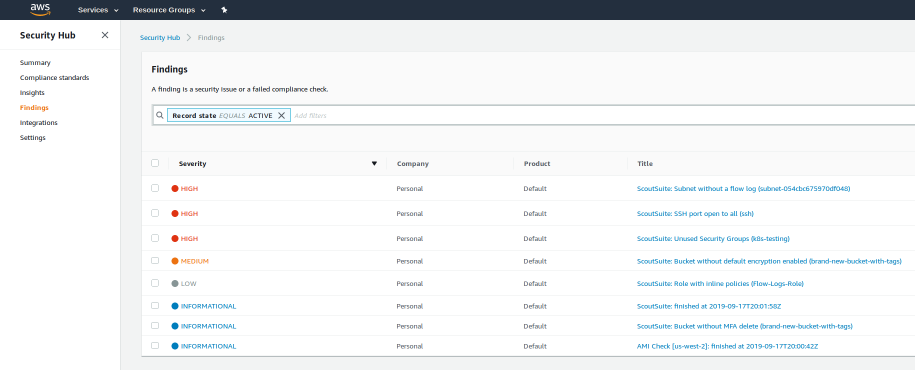
Our initial prototype for CirrusScan didn’t include any way to conveniently view findings that were discovered, but fortunately AWS announced Security Hub in late 2018 as a way to “centrally view and manage security alerts and automate compliance checks.” All we had to do was translate any findings we generated into a common format that’s recognized by Security Hub, and suddenly we had a dashboard we could use for CirrusScan. And, Security Hub allows multiple accounts to be linked in order to share findings. With this setup, our primary Audit account could serve as the master Security Hub account (with access to all findings), while developers could view their own findings specific to each of their accounts by using Security Hub within their own member Security Hub accounts.
Security Hub Console:
Execution schedules
Next we had to decide how often our checks should run. Just running some of the configuration-based checks once a day seemed too infrequent; if an S3 bucket was publicly readable, we didn’t want to wait until the next day to find out about it. We settled on using CloudWatch rules to run the initial checks once every 4 hours, which would provide same-day notification of any potential misconfigurations made by development teams.
Some of our later checks, like the vulnerability scanner, were more resource intensive and communicated with third-party APIs, so we didn’t necessarily want to run those every 4 hours. We implemented alternate CloudWatch rules to define weekly and monthly schedules to run those checks on a less frequent basis.
Another key feature we wanted to provide was the ability to request one or more checks on-demand, so we put an API gateway in front of our check scheduler. This provides the ability for developers to request one or more checks to be run against their accounts at any time.
More than just configuration
Several of the tools we looked at generate security findings based strictly off of AWS configuration data. AWS Config does this, as well as an open source tool called ScoutSuite. Many of the potential security issues that we wanted to detect as soon as possible were common misconfigurations such as inadvertently exposing an S3 bucket publicly, or creating overly permissive security groups, and so we settled on ScoutSuite early on as the first type of scan to perform using this framework.
Evaluating rules against configuration data, while important, wasn’t the only thing we wanted to scan for. We added additional custom checks to verify that only approved AMIs were used to provision EC2 instances, and that those instances were being rotated regularly to ensure that only up-to-date software and operating system distributions were being used. We also wrote additional checks that examined VPC flow logs to see if specific or unusual network traffic patterns were detected.
To take further advantage of the fact that we were now running checks inside the target AWS account, we developed still other tests using nmap to perform scans against specified target subnets, and another that performs vulnerability scans against EC2 instances in an account. Now we’re able to perform a network-level test from inside the VPC, and report any findings via Security Hub. Similar tests could use tools like the metasploit framework.
Case Study: Vulnerability Scanning
After developing several of these configuration and port scanning checks, we wanted to further advance our scanning capabilities by creating a check that utilizes the industry standard Nessus vulnerability scanner. This check gave us the ability to test against a wide spectrum of operating systems, application and web servers, databases, and other critical infrastructure. We already had experience using Nessus with our on-premise systems.
Our on-premise environment has different network zones that allow us to use one Nessus box per zone to scan against the thousands of resources in it. Pretty straightforward. In our cloud environment, though, we were faced with a challenge because we needed to scan hundreds of AWS accounts that are completely isolated from each other (we intentionally restrict cross account access and VPC peering between accounts for obvious security reasons). Having a centralized Nessus scanner was not an option.
CirrusScan works perfectly for this because we can use the containerized framework to spawn individual Nessus scanners on the fly within each account, perform scans, and terminate the scanner after each execution. This solved three things for us:
- We didn’t have to leave EC2 Nessus scanner instances running in each account
- We didn’t have to open any network ACLs to scan from a single source scanner
like we did in our on-premise environment, as the scanner in each account is
exclusive to that account - It helped us meet PCI regulatory requirements to scan for all accounts
handling PCI traffic on a recurring basis
Vulnerability Scan Workflow:
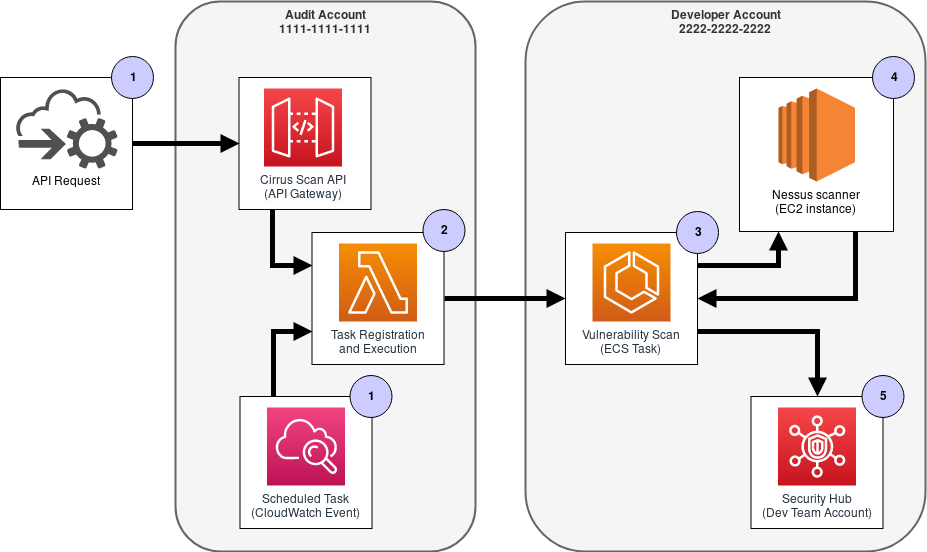
We use a role-based access approach so that we can control who initiates CirrusScan checks. Users can trigger vulnerability scans on their own account or on multiple accounts, depending on their authorization. Here’s a step-by-step run down of the above workflow:
The action begins when an API request is received via the API gateway, or
when a CloudWatch scheduled event occurs.Next, the CirrusScan lambda in the Audit account looks at the incoming
request and registers ECS task definitions in each of the target accounts.In each target account, the ECS task is started, and performs the following:
- Provisions an EC2 instance running the Nessus scanner
- Queries the account for running resources to generate a list of scan
targets - Launches the scan with the identified scan targets
- Evaluates the scan results and reports any findings into Security Hub
- Deprovisions the EC2 instance running the Nessus scanner
What’s Next?
The ability for developers to initiate their own security scans means that they can integrate continuous security best practices into their CI/CD pipelines. Plans are in the works to incorporate static and dynamic code analysis tools to the suite of checks that developers can use. For example, fuzz testing could be performed against any products that expose an API. In addition to the typical unit and integration tests, developers will be able to perform these kinds of security assessments against their products before ever deploying them to production environments!
Any findings discovered are automatically added to Security Hub, but we’re working on notification and reporting mechanisms that will notify developers of a problem without them having to first access the Security Hub console. Using SNS topics, we’ll be able to publish findings that developers can consume via their preferred notification mechanism, be it Slack, email, or a third-party ticketing system.
We’re also exploring the possibility of using the CirrusScan infrastructure to scan on-premise resources external to AWS. We’d gain the benefits of flexibility and scalability, and provide additional protection for projects that have yet to be migrated to AWS.
So far, the findings provided by CirrusScan have proven helpful to identify potential security issues in a cost-effective and timely way. We’ve used it for all kinds of environments, ranging from development and experimental projects to ones running in production.





