
Key takeaways
- Governance at scale breaks down when reviewers must manually reconstruct evidence across many systems — not because the tiering standard is wrong.
- TrustTier treats tier governance as an agent problem: it gathers signals from existing systems and reasons across assigned, intended, and qualified tiers.
- Using the same certification logic for verification, review, and audit lets governance keep pace as the data lake grows.
Modern companies run on data. Applications generate it constantly — every checkout, every login, every background job emits something worth keeping. That data flows into a data lake, where it gets cleaned, joined, modeled, and reshaped into the tables that power everything downstream: dashboards, machine learning models, financial reports, and the customer-facing features that depend on knowing who did what and when.
The teams producing that data and the teams consuming it are rarely the same. A producer publishes a table. A data scientist three organizations away builds a model on top of it. A finance team reports against it. An ML pipeline retrains on it nightly. None of them wrote the original code, and most will never talk to the people who did. What they need — what they have to be able to assume — is that the table is what it claims to be: documented, reliable, and worthy of the decisions being made on top of it.
That assumption is what data governance exists to safeguard. It helps teams find, trust, and use the data they need — improving discoverability, usability, and reliability with the right level of control for each dataset. In a growing data lake, maintaining that balance comes down to reviews: more tables mean more checks, more systems to coordinate, and more back-and-forth between the teams that produce data and the teams that govern it.
At GoDaddy, we manage thousands of tables in our data lake — including hundreds that require elevated governance — and more are onboarding each day. At that scale, keeping up with reviews is the challenge. Our data lake ranks datasets from Tier 5 (minimal governance) through Tier 0 (highest trust) — lower tier numbers mean higher trust. Central to the process is the dataset tier review — determining whether a table qualifies for the higher-trust tier its producer intends to tier up to. Reviewers gather evidence across systems: data quality and delivery trends against promised SLAs, captured lineage, design documents, data flow and model diagrams, and endorsement from both producer and consumer — among other requirements for the intended tier. What starts as a manageable review — a checklist here, a manual audit there — does not stay manageable for long. Governance has rarely kept pace, and the process built to create trust can end up slowing everything down instead.
Not every dataset carries the same level of risk or importance, which is why tiers exist in the first place. They set minimum standards for producers, signal reliability for consumers, and give governance teams a structured way to monitor, review, and audit changes. The tiering standard behind those reviews is sound — the problem was never the rules themselves, but the manual effort it took to apply them at GoDaddy's scale.
Why manual reviews broke down at GoDaddy
That review process was not keeping up. Governance for our most trusted datasets spans multiple systems of record. Each system holds part of the picture:
- Alation — the source-of-truth data catalog exposed to consumers for discovery, stewardship, and metadata
- Data Lake Management Services (DLMS) — GoDaddy's API for checking lineage, SLAs, and other operational signals
- Confluence — where producers publish design documentation and process artifacts
- DataWorks — where producers onboard tables and manage data lake assets
- GitHub — where code and data model diagrams live
Together, these systems hold the evidence reviewers need — SLAs, quality signals, endorsements, and more — to determine whether a dataset meets its tier requirements.
But when that story has to be reconstructed manually for every review, the process becomes fragile.
To determine whether a dataset met its intended tier, reviewers had to gather evidence across multiple systems, interpret requirements, and manually verify a long list of checks. The work was fragmented, repetitive, and difficult to scale. Reviewers had to know where to look, what to compare, and how to interpret edge cases. Producers had to understand which requirements applied to their intended tier and where evidence was expected to live. Even when everyone was aligned, the process still depended on repeated human effort to collect, validate, and reconcile the same kinds of signals over and over again.
For data producers, the process could feel opaque and slow. For governance teams, it created a growing operational burden. That is not a sustainable model for a growing data platform.
We asked a simple question:
What if tier governance worked more like an intelligent review system than a manual audit process?
That question led to TrustTier.
From manual reviews to guided certification
TrustTier started as a three-day hackathon prototype in March 2026 and is still in development. We are building it as an AI-powered data tier governance agent to automate how datasets are verified, reviewed, and audited.
At a high level, the experience we are designing is intentionally simple. A producer provides three pieces of information:
- the database name
- the table name
- the intended tier
From there, TrustTier is designed to do the heavy lifting.
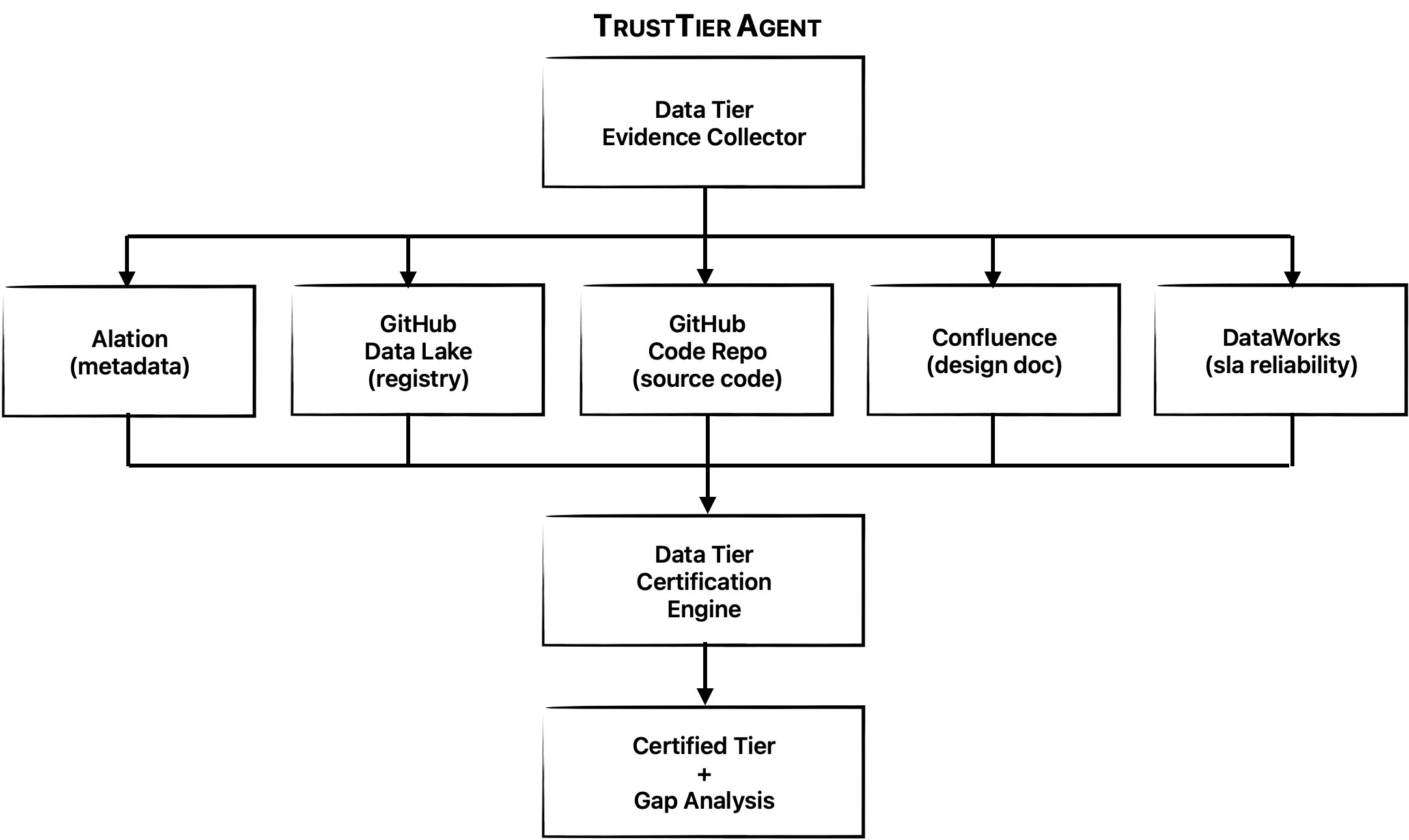
It gathers evidence across the systems where governance signals already live, checks metadata, documentation, lineage, reliability, and endorsements, applies the tier requirements matrix, and produces a certification report that explains what the dataset qualifies for, where gaps exist, and what should happen next.
What used to require manual coordination across several tools would become a single guided workflow — pulling together the same signals that are already scattered across Alation, DLMS, Confluence, DataWorks, and GitHub.
The following diagram shows the general architecture of the TrustTier agent:
What makes TrustTier different
It would be easy to think of TrustTier as just a better interface for a checklist. But that is not really what it is.
TrustTier behaves more like an agent than a form or chatbot. You could ask a chatbot the same question — "Does this table qualify for Tier 2?" — and get back an unstructured list of everything it found across systems. TrustTier applies the tier requirements matrix, selects the tools it needs, and returns a prioritized assessment tied to the intended tier.
Consider a producer tiering up a table from Tier 3 to Tier 2. TrustTier streams progress as it checks Alation, the data lake, and delivery reliability. The certification report shows the assigned tier in DLMS (Tier 3), the intended tier (Tier 2), and 12 of 13 checks passing — including a data steward, linked code repository and design doc, 11 upstream dependencies, a configured SLA, and 100% delivery success over 28 days, well above Tier 2's 90% requirement. Two gaps block the tier-up: no valid Mermaid entity-relationship diagram in the GitHub repository, and no data consumer endorsement in Alation from someone outside the steward team. Rather than listing those findings equally, the report explains where each gap lives, what is required to close it, and which to fix first — surfacing facts is not the same as reasoning over them.
That distinction is important.
Data governance is not just a search problem. It is also a judgment problem. A useful governance agent has to understand the difference between what a dataset is currently assigned, what it is intended to become, and what it can actually qualify for based on evidence.
TrustTier is being built around that model.
It reasons across three tier states:
- Assigned tier: the currently approved tier recorded in systems such as DLMS and Alation
- Intended tier: the requested or planned tier coming from a PR, ticket, or audit context
- Qualified tier: the tier the dataset actually meets based on documented requirements and available evidence
That allows the system to do more than answer "does this pass?" It can also explain whether an intended tier is realistic, what is missing, and how far away the dataset is from qualifying.
What the agent actually checks
The underlying logic comes from the Data Tier Requirements Matrix, which defines what evidence is required at each tier. At higher trust tiers, requirements are stricter — datasets must satisfy tougher documentation, reliability, and endorsement checks before they can be trusted for broader use.
TrustTier checks requirements from the matrix, such as:
- Is there a designated data steward, and have the data producer and consumer endorsed this dataset?
- Does the table have a code repository and design document?
- Are primary keys, table descriptions, and column descriptions documented?
- Are data model and flow diagrams available?
- Is lineage captured?
- Does the dataset meet the delivery reliability expectations for its tier?
On their own, none of these checks is especially novel, and this is not an exhaustive list. What matters is the ability to evaluate them consistently, across systems, and in a way that produces a coherent certification outcome.
That is the role TrustTier plays.
A better experience for data producers
TrustTier is being built to provide not only efficiency in the review process, but also clarity for data producers.
Imagine a producer who wants to tier up an existing dataset. In a manual process, they may need to read through a long requirement list, locate artifacts across those same systems, interpret ambiguous standards, and then wait for a governance review to learn what is still missing.
With TrustTier, that process would become much more direct — producers would get a certification report showing what tier the dataset qualifies for, which requirements pass, which are missing, and what to prioritize next.
That makes governance feel less like a gate and more like a guided path.
Instead of discovering issues late in the process, producers would see gaps early. Instead of waiting for a reviewer to stitch together the evidence manually, they would get a structured answer. And instead of treating governance as a separate operational burden, teams could incorporate it more naturally into how datasets are developed and improved.
Standardizing verification, review, and audit
TrustTier is designed to support the full lifecycle of tier governance.
For verification, a producer will be able to ask for an assessment of any dataset and receive a certification report in chat.
For review, the agent will support a formal tier-up workflow triggered by a Jira ticket or data lake PR (a pull request to the data lake repository to register or modify tables), using the intended tier defined in table.yaml — a configuration file that serves as the data contract between producers and the data lake, capturing metadata, access settings, and lineage for each table. After the review, the assigned tier reflects the lower of the intended and qualified tier.
For audit, the same certification logic will be applied on a schedule to validate that already-governed datasets still meet their tier requirements over time.
This consistency across verification, review, and audit is one of the most important design choices in the system. It means the same logic can be reused across governance workflows rather than reinvented for each one.
Why this matters beyond automation
Governance is fundamentally about confidence — that a high-trust label reflects reality, that the path to a higher tier is fair, and that enforcement is repeatable and auditable. TrustTier aims to build that confidence by standardizing reviews, systematizing evidence gathering, and replacing manual interpretation with transparent certification reports.
Where TrustTier is today
The current prototype is a lightweight, CLI-based tool that evaluates the tier of a dataset by aggregating governance signals across multiple systems, applying a configurable rule-based framework, and producing transparent, explainable certification results. In early testing, it successfully evaluated datasets end-to-end, assigned reasonable tiers based on available signals, and demonstrated that the approach could scale.
We are now moving into Phase 1, which expands that rule-based foundation into a unified tier governance agent with baseline validation integrated into data lake PR workflows and scheduled audit pipelines. The focus is on verifying that required governance artifacts exist across Tier 1 through Tier 3 datasets, providing early feedback during reviews, and tracking compliance over time.
Closing thought
TrustTier is an early example of how AI agents can help modernize governance by doing what humans should not have to do repeatedly: gather scattered evidence, apply the same standards over and over, and translate complex requirements into clear next steps.
As data ecosystems continue to grow, the real opportunity is not just to govern more data. It is to build governance systems that are worthy of the scale they are meant to support.





