
Key takeaways
- Success with AI coding agents comes not from perfect prompts but from establishing effective workflows and feedback loops that treat the AI as a learning collaborator rather than just a tool.
- Providing context through repository documentation, upfront design, and incremental task complexity helps coding agents produce consistent, high-quality code that matches your codebase's patterns and practices.
- To maximize productivity with AI coding agents, implement structured feedback loops, use knowledge graphs for cross-session context, and gradually increase task complexity as the agent demonstrates mastery.
Hero image Generated by GoCaaS MCP and Claude Desktop
Got your attention? (Claude thought that title was the funniest on his list of 10 suggested titles.)
My breakthrough with AI coding didn't come from discovering the perfect prompt— it came from fundamentally changing how I approached the relationship. When I shifted from treating coding agents as sophisticated autocompletion tools to seeing them as adaptable collaborators in a deliberate learning process, all previous skepticism about the technology evaporated. This is not a tool chain you can incrementally adopt— you have to fully commit.
I sometimes get the question, "Would you mind sharing your prompts with me?" The reality is that I don’t have many saved prompts. I've discovered something counterintuitive— canned prompts aren't the secret sauce. There’s no more magic combination of words needed to write a prompt (models are good enough to understand intent). What matters far more is establishing effective workflows and feedback loops with your coding agent. The real magic happens in how you structure the conversation, build context, and guide the agent through increasingly complex tasks.
These tips aren't about what to say to your agent, but how to build a productive relationship with it— one that consistently produces high-quality code with minimal human intervention. Think of it less as command-line arguments and more as pair programming with a junior developer who never gets tired, never complains about repetitive tasks, and doesn't raid the Kirkland kombucha tap.
I primarily use Claude Code and Claude Desktop, so there may be some nuances specific to Anthropic models. Discussions with colleagues at GoDaddy using Cursor, Copilot, and other tools indicate these tips and techniques are tool and model agnostic.
 Claude assisted in the writing of the document. The Claude icon indicates specific ideas that came directly from the model.
Claude assisted in the writing of the document. The Claude icon indicates specific ideas that came directly from the model.
1. Have the coding agent read and document your repository
Ensuring the agent has a basic understanding of your code base can dramatically improve task accuracy. The agent will follow the patterns and styles found in the code, leading to better, personalized results.
Technique - Have the coding agent review your code base before starting work. If this is the first time you’ve used the agent in a repository, have it write its summary in the code base for future use. Instruct the agent to identify the best practices for the repo and common implementation patterns.
With the context in memory, I find it helpful to tell the agent (I use backticks for code symbols):
I want you to implement
handler.Bsimilar to the way I did it forhandler.A.
Tip - Claude Code has the command /init that performs context gathering and creates a CLAUDE.md file in the repository. Claude also has a /memory command that allows you to edit CLAUDE.md files found in parent directories (back to ~/.claude).
Tip -  Cursor provides a sophisticated system for defining reusable rules files that perform a similar function as CLAUDE.md files.
Cursor provides a sophisticated system for defining reusable rules files that perform a similar function as CLAUDE.md files.
2. Big(ish) upfront design
The likelihood of the agent "going off the rails" increases with task size. Providing detailed guidance through design artifacts and software models provides guardrails for LLM generations.
Technique - create design documents, models, and interfaces before asking the coding agent to begin working on tasks. Providing detailed context constrains the agent’s creativity and results in more consistent implementation results.
Let's design a task list system. It's going to be a REST API using PostgreSQL as storage and React App front end. The model will look like this:
type Task = {
id: string,
name: string,
description: string,
completed: boolean,
}
interface TaskManager {
CreateTask(task: Task): Promise<void>
UpdateTask(taskId: string, updates: Partial<Task>): Promise<void>
DeleteTask(taskId: string): Promise<void>
GetTask(taskId: string): Promise<Task>
ListTasks(): Promise<Task[]>
}
The REST API should have endpoints mapping to the `TaskManager` interface (e.g. `GET /api/v1/tasks`, `GET /api/v1/tasks/:taskId`, etc.).
You will implement the `Task` model and `TaskManager` interface.
The TaskManager will be injected into handlers.Tip - Iterate on the architecture with Claude Desktop and have it assist in designing the implementation plan. Have Claude Desktop write the plan, designs, and initial code to disk. Instruct the coding agent to read the artifacts before beginning its tasks.
3. Hard problems for humans are likely hard problems for agents
If you think I don’t know how I would do this, the model probably won't either.
Common Failure Modes: Agents continue to struggle with optimizing complex database queries, securing critical code, and solving complex algorithmic problems. Be prepared to provide more guidance in these areas or break them down into smaller, more manageable components.
Technique - Take the time to decompose the problem into smaller tasks. Spend time researching solutions. Iterate with the model, exploring solutions instead of rushing to implement the feature. Breaking down complexity benefits both you and the agent.
Tip - Claude Desktop’s “Deep Research” mode is an excellent way to get advice from the web.
4. Tell the agent to ask clarifying questions
Models are biased toward accomplishing a user's goals even when those goals are ambiguous. The consequences of ambiguity can be profound. An LLM can generate a massive amount of changes to a codebase in minutes, resulting in noise (and complexity) that the developer will have to correct. Worse, the erroneous changes will pollute the context, including tasks and outputs you don't want, skewing the accuracy of future generations.
An easy solution for mitigating ambiguity is to have the model ask for clarifications.
Technique - Instruct the agent to ask you clarifying questions if they are uncertain about a task. You might find enlightening holes in your thought process! However, most of the time, this will help guide the model, and the act of telling it to ask questions once will encourage the agent to do it throughout the session.
Let's create a new Golang MCP server. Start by reviewing the guidelines about how to implement MCP servers in Go (project documentation). It will be called "mcp-elasticsearch" and will provide automations around the use and management of Elasticsearch. Set up the project boilerplate but stop before you start adding tools. We are going to use the official client:
go get github.com/elastic/go-elasticsearch/v9@latest
When we implement this, we don't need an API abstraction. We can inject the Elastic client directly into tools and use it there.
IF YOU HAVE QUESTIONS, ASK THEM!!!! Don't operate in ambiguity. Ask me first and then we will continue with the implementation.5. Feedback loops
Probably one of the most critical tips in agentic coding is to establish feedback loops. Feedback is more than just comments from the user, and should include:
- Your comments and requests regarding the implementation.
- Compilation, unit test, and integration test results.
- Errors encountered by the user when using the code.
- Screenshots (discussed in section 7).
- CICD and deployment errors (if applicable).
- Log entries.
Agents (like people) are most effective when they receive feedback and can reason and adapt.
Technique - Start all sessions by building the feedback loop. This might involve providing explicit instructions to the agent, instructing it to validate its work by compiling the codebase, running unit tests, and executing the application after each task. Instruct the agent to continue refactoring until the verification mechanisms are successful. You can even have the agent create the verification mechanism; however, be careful. Agents are known to change unit tests to make them pass (instead of fixing code). You may need to instruct the model never to change the tests. Provide the agent with the ability to request that you verify the validity of a test. Otherwise, the agent may infinitely loop trying to accomplish an unachievable task.
At the end of every task, please validate the results by doing the following:
1. Compile the server
2. Run unit tests
3. Run the linter (if applicable -- run `go fmt` for Golang code)
4. Run integration tests
If any of the verification results fail, refactor the code until they pass. DO NOT CHANGE THE TESTS. If you can't make the implementation work after 10 attempts and believe the test code may be the problem, stop working and provide me details on what is not working.Tip - Resist making code changes yourself. When you do that, the agent has no context for the changes (it will only know there are changes by calling git diff). Force the agent to make the changes so it can learn – or, if necessary, make the change and ask the agent to observe it by reading the file or calling git diff.
6. Ramp-up, particularly with repetitive tasks
Coding agents are excellent at pattern matching and mimicking code. You can improve the accuracy of the agent by perfecting a single example and then having the model scale to multiple examples.
Technique - The ramp-up method transforms your agent from a novice to an expert through incremental learning. Begin with the simplest possible task, then provide feedback by guiding the agent so it learns from corrections. After the agent completes the initial task, assign a second similar task and observe how it applies previously learned patterns.
Gradually increase the complexity by asking the model to complete two tasks, then three, then five. This progressive scaling builds the agent's pattern recognition and consistency. When the agent demonstrates mastery in handling small batches, transition to scale— have it generate a task list file with all remaining work organized in manageable batches. The agent can then methodically work through each batch, applying its accumulated knowledge across dozens of similar implementations with minimal oversight.
This is an example from the mcp-spotify server we built internally:
Our next task is to "thin out" the data returned by the mcp-spotify server to the MCP client (LLM). The issue is that Spotify returns way too much information. We are going to apply a general strategy across the MCP server to handle this. We will create functions for each model type we currently return (e.g. spotify.FullTrack, spotify.FullAlbum, etc.) that accept a list of fields to return. We will then thin the model by only providing those fields (using a `map[string]any` as the return type is fine). Then tools that provide those model types will have parameters the specify the fields to return. For example, we would have fields `fieldsAlbum` and `fieldsTrack`. Fields thinning parameters should always have sensible defaults. For most use cases, the user and LLM don't need a ton of information.
Let's start by thinning the `get_album_tracks` tool. Remember, we want to be able to reuse the "thinning" functions. So for common types create resuable functions. Also, feel free to provide a more appropriate name than "thinning"Correct the task instructions:
Looking at the response from some of our models, when we run the projection and filter out values, we are getting the `null` result for many:
{
"albums": [
{
"name": null,
}
]
}
Adjust the schema definitions to use `omitempty` Follow up with:
Let's apply the same projection logic to the `get_albums` toolNext:
OK, let's do the same projections on `get_artist_related_artists` and
`get_artist_top_tracks` tools.Then:
Perfect, let's set up projections on `get_artists`, `get_available_devices`
and `get_categories`Try a big batch:
OK, let's do `get_tracks`, `get_user_profile`, `get_user_saved_albums`,
`get_user_saved_episodes`, and `get_user_saved_tracks`Finally:
Write the remaining tools that need thinning to the file `thinning_tasks.md`. Group tools into batches of five. Finish the rest of the thinning process by reading the thinning_tasks.md file and taking the next match (mark the tasks that are finished when you are done).7. Most agents can "see" not just "read"
Many models, including Claude Haiku, Sonnet, and Opus, are multimodal (capable of understanding not just text, but also images and files). Images, in particular, can be used by the agentic coder to resolve UI issues or iterate on a design.
Technique - Provide screenshots showing problems. I find this particularly effective when I encounter UI bugs and I'm using the agent to create the UI. Visual context often communicates issues more clearly than textual descriptions alone. The following image demonstrates Claude Code and the Playwright MCP server resytling a UI:
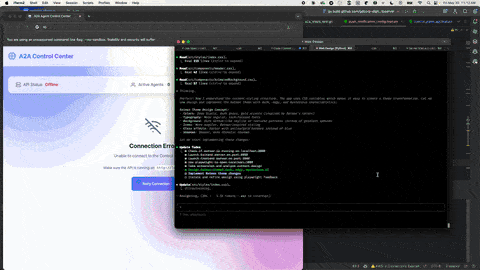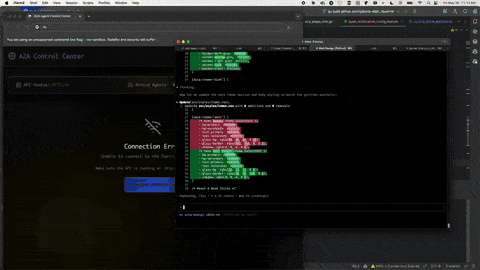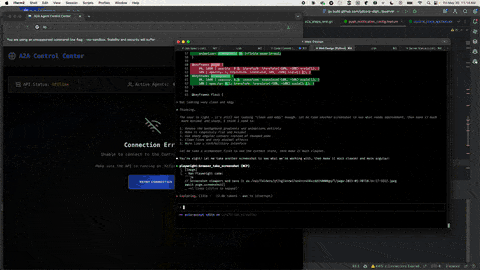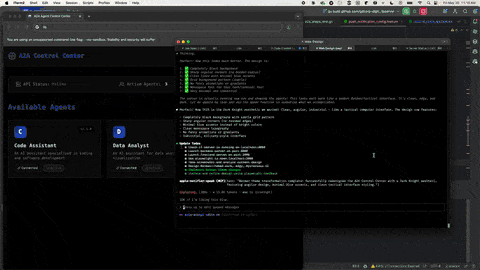
8. Use multiple agent sessions simultaneously to maximize productivity
Most engineers will quickly find themselves utilizing multiple instances of their agentic coder, allowing them to multitask effectively. There is no magic to this process; simply start another instance of the application (e.g., on the terminal: bash> claude).
The difficulty of multitasking with agents is ensuring that running tasks don’t impede each other. My preference is to have a single agent working in a code base, generally wanting to avoid merge conflicts. However, different strategies allow multiple agents in the same codebase:
- Run agents in specific directories and force the agent to isolate changes to that directory.
- Clone your project multiple times and run agents on different branches.
- Use Git worktrees
Git Worktrees - Anthropic recommends using Git Worktrees for tracking simultaneous (but distinct) tasks in a codebase (Common workflows - Anthropic). My limited experience with this was confusing, but don’t let that stop you!
Is it effective? I can work on three projects at a time with constant attention (agents finishing tasks every 5-10 minutes). I can also manage two projects while engaging in other activities (such as listening to a meeting, watching TV, or exercising – yes, I’m somewhat obsessive). Using multiple agents as a strategy tends to make me significantly more efficient, but has an upper bound on effectiveness since my style leans towards micromanaging agents (having them complete tasks with high accuracy and limited looping). However, this isn’t the only way to work with an agent (GoDaddy Senior Principal Engineer Jay Gowdy runs his agents for hours without intervention).
9. Let the Agent Speak to You
If you are working on a bunch of tasks simultaneously, it’s helpful to know when a coding agent completes a task. If you have a ton of windows open, you’ll quickly find yourself losing track of what is happening.
Technique - Have the coding agent “speak” a summary of the task it accomplished before returning control to the user.
An important MCP server macOS users can install is the apple-notifier. This will install a tool called speak, which allows MCP clients to send a message to Apple’s text-to-speech service on the laptop.
I’ve added a directive to Claude Code to always provide a summary of its work at the end of a task:
At the end of every task (or group of tasks), before returning control to the user, please provide a 1-2 sentence summary of what you accomplished and use the `speak` tool to play the summary audibly.Tip - You can adjust the default system voice in the Voice (Spoken Content) section of the macOS settings. This is not completely necessary since the apple-notifier MCP server does allow you to specify the voice as a parameter. However, I prefer using the default, which makes the prompt simpler. Also, I recommend Siri because it has the most natural-sounding voice:
The following is an example of the speak tool invocation:

10. Use Knowledge Graphs for Cross-Tool, Cross-Session Context Management
Learning how to manage the LLM context is the key to successfully using a coding agent. Unfortunately, many of the tools we use are designed to manage context within a single session. As you become more proficient in refining your core workflows, you will begin to develop a library of standard instructions and preferences that you want applied generally and in specific scenarios. Many coding agents include a mechanism to reuse context across sessions, but none are designed to do it across applications.
Technique - Use an MCP server to manage your personal Knowledge Graph (KG) to save and use context and preferences across sessions.
A KG is a structured semantic network that represents entities, their attributes, and the relationships between them in a machine-readable format. It organizes information as a connected graph of nodes (entities) and edges (relationships), enabling complex queries, inference of new knowledge, and cross-referencing of information across domains. Unlike traditional databases, KGs excel at capturing context and relationships between disparate pieces of information, allowing for more intuitive navigation of complex information spaces and enhanced pattern recognition.
I started with the official memory MCP server for managing my KG but quickly grew out of that implementation (it has terrible search) in favor of Neo4j’s tool-compatible alternative.
The key to integrating a KG into your workflow is to ensure your preferences prompt (the first thing loaded by agents) includes special instructions on how to use it.
This is an example of my preferences:
<userPreferences>
...more above...
3. KNOWLEDGE GRAPH
- A Knowledge Graph is provided as the `memory` MCP server
- Any command shortcut following the pattern `/{command}` should consult the Knowledge Graph for details or explicit instructions. I keep prompts and hints there.
- Use the `search_nodes` feature to find relevant entities related to my requests. If you are unfamiliar with what is available, use `read_graph` to understand the context saved.
- The Knowledge Graph includes a `command` entity type with entries for each command.
- Load observations from the Knowledge Graph for that command and then execute the request.
- Never invent commands.
</userPreferences>When I start a new chat, the agent will often first execute a memory:search_nodes to find potentially relevant information. If I use the pattern /, the agent will first search for the command in the KG, and if one is found, it will bring the relevant context into the conversation before acting on the request.
Bonus - Two things Claude thinks you should know:
11. Version Control Integration
Agents excel at generating high-quality commit messages and PR descriptions, which significantly improves code review efficiency. Train your agent to follow your team's commit message conventions and PR templates. This not only saves time but also creates a more consistent and informative version history. Consider having your agent prepare commit messages that explain the rationale behind changes, making future maintenance easier.
12. Organizational Integration
Integrating agentic coding into existing team workflows requires thoughtful planning. Establish clear guidelines for distinguishing between agent-generated and human-written code, particularly for critical components. For code reviews, indicate which parts were generated by the agent to set the appropriate context. Create a team knowledge base of effective prompts and strategies. Consider running lunch-and-learn sessions to share best practices across the team. The most successful integrations typically start with non-critical components to build team confidence in the approach.
Conclusion
Learning to code agentically isn't something you do with 10% of your time or attention. This is fundamentally a new way of operating that demands full immersion. The productivity frontier isn't found in crafting the "perfect prompt" but in developing a symbiotic workflow with your digital counterpart.
Expect two to three weeks of reduced productivity before seeing significant gains, though I think many people become productive faster. The first week typically involves frequent corrections and guidance as you both learn to communicate effectively. By the second week, you'll have developed reliable prompt patterns and workflow habits. By week three, you'll begin to see productivity improvements that justify the investment.
What began as a curiosity in my workflow has fundamentally transformed my approach to software development. Engineers who embrace it will experience a force multiplier for their creativity and problem-solving abilities. The code may be written by an AI, but the architecture, vision, and innovation remain uniquely human. For now, at least. 💀





{kind=link}