
Background
At GoDaddy, the art and science of experimentation is a vital thread in the fabric of our product development and marketing. Our internal experimentation platform, Hivemind, is a testament to our commitment to cultivating a company-wide experimentation culture. Conceived in 2020, Hivemind phased out numerous external experimentation platforms in favor of a single standardized, in-house solution for configuring and analyzing controlled experiments.
When we first introduced Hivemind, it functioned as a minimum viable product, lacking the safeguards to prevent poor experimental practices. The basic setup and stats engine led to bad practices. These included p-hacking, ignoring the need for adequately powered experiments, and mixing up Bayesian with frequentist methods (among other issues).
Extensive training on experiment best practices wasn't an ideal solution to get experimenters company-wide up to speed quickly. Instead, we needed a mix of basic training and platform enhancements to help guide and incentivize experimenters to design optimal experiments. In this blog post, we'll delve into several key improvements we've made to Hivemind to shape the experimentation culture at GoDaddy.
Categorizing Scorecard Metrics
Scorecard templates in Hivemind consist of experiment metrics that experimenters use in their analyses. These templates often contain numerous metrics, enabling experimenters to uncover actionable insights. However, experimenters frequently fall prey to confirmation bias, treating all scorecard metrics equally and selectively focusing on metrics that indicate a successful experiment outcome. This practice inadvertently increases the false positive rate of their experiments. To mitigate this issue, the Hivemind platform requires experimenters to categorize scorecard metrics into three distinct groups before launching an A/B/n experiment:
| Decision Metrics | Guardrail Metrics | Informative Metrics |
|---|---|---|
| Directly measures success or business value | Ensures the experiment does no harm to the business | Provides additional insights but are not critical to decision-making |
Along with requiring experimenters to categorize their metrics, Hivemind displays the two more important categories (decision and guardrail) more prominently at the top of their scorecard than the lesser important informative category.
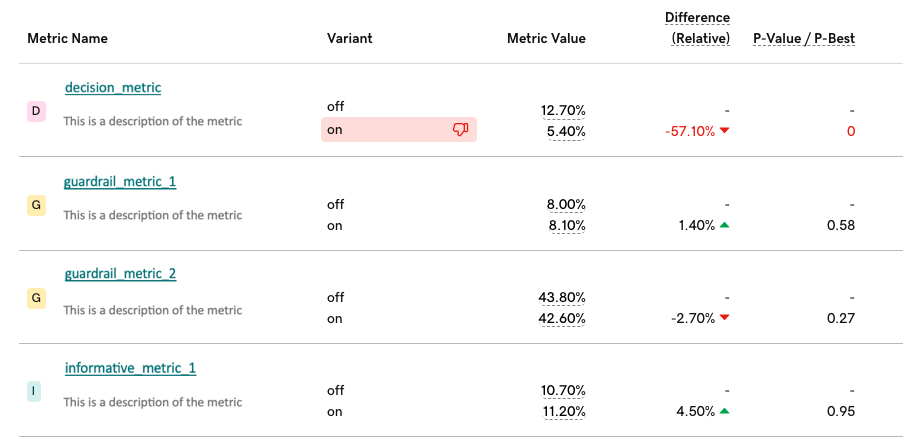
Categorization provides a more straightforward framework for analyzing experimental outcomes and incentivizes experimenters to choose metrics thoughtfully, thus streamlining the path to accurate conclusions.
Requirements for New Feature Utilization
As we matured the Hivemind platform, supporting Bayesian and Frequentist analyses became challenging. The data science workload naturally doubled as we explored new statistical features like early stopping and false discovery rate adjustment for Bayesian and Frequentist. We decided to support only Frequentist methods because they are computationally inexpensive. Additionally, Frequentist outcomes are binary, making it easier for less-experienced experimenters to make decisions. We tried to remove Bayesian features from the platform, but teams already built supplemental dashboards and playbooks leveraging Bayesian fundamentals. We decided to persuade teams to switch to Frequentist by leaving Bayesian features unchanged and only introducing new platform features to Frequentist experiments.
To leverage the following newer Hivemind features, teams needed to configure a Frequentist analysis and attach a power analysis using our internal power calculator tool powered by our open-source Python code:
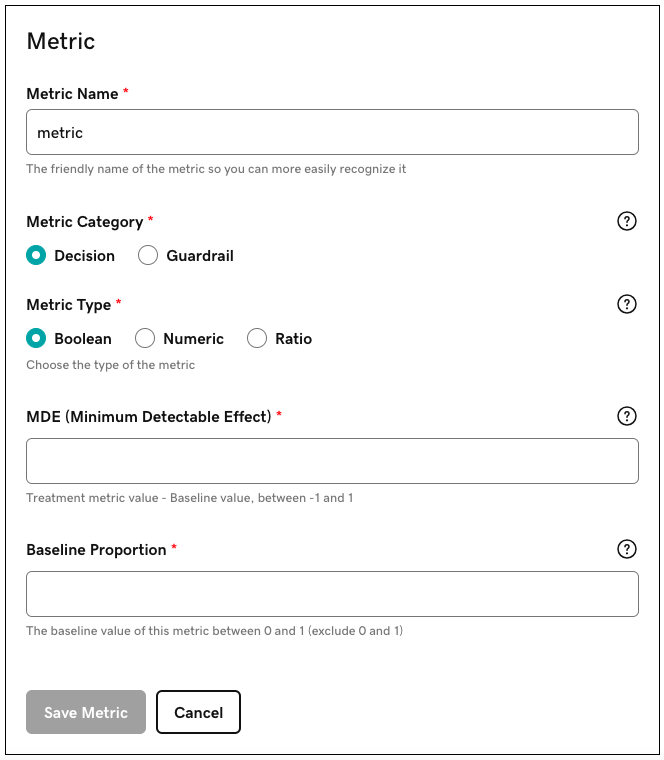
- Early stopping - Our platform can support experiments designed without a fixed sample-size. In some circumstances, these "sequential designs" allow experimenters to conclude experiments earlier than they would with a fixed design. For properly configured experiments, our platform can leverage both designs in parallel, and experimenters can have the best of both worlds.
- Segmentation insights - Experimenters can quickly identify and explore significant user segments through the platform, enhancing their ability to draw meaningful insights from their data.
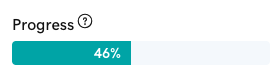
- Progress bar - By displaying the completion percentage, experimenters understand when they have sufficient data to conclude their experiment.
When an experimenter does not embed a power calculation, a warning displays at the top of the report:

Embedding power calculations and standardizing our analysis allows us to share valid customer insights across numerous teams at GoDaddy.
Automated Conclusivity
Another difficult challenge we faced was the tendency of teams to fish for "interesting" results, even where there might be none. Despite clear guidelines for correctly concluding experiments, win rate goals incentivized teams to find evidence of a winning experiment. Numerous teams’ self-reported win/loss rates were optimistically marked at over 50%.
We implemented automated conclusivity within the Hivemind platform to counteract this and ensure the integrity of experimental conclusions. This automation brings several benefits:
- Objective conclusion tracking - We eliminate the optimistic bias that teams may have when reporting outcomes, allowing us to trust the results and learn what truly influences our customers.
- Impactful leadership oversight - Leadership can more accurately assess the true impact of experiments, free from inflated annual revenue projections based on inconclusive experiments.
- Configurable metric prioritization - The platform empowers users to prioritize their decision and guardrail metrics during the setup phase of an experiment. This ensures that the platform can automatically conclude based on the significant results from higher-priority metrics.
The automated system in the future will include functionality to conclude experiments early based on the sequential analysis. It will make a conclusion when a decision or guardrail metric reaches significance, enabling faster decision-making.
Platform Badging
Enhancing the quality of experimentation is a cornerstone in deriving actionable insights and guiding impactful decisions at GoDaddy. We developed badging levels – bronze, silver, gold, or platinum – to allow experimenters to assess the quality of the experiment/insights quickly. Bronze experiments are the lowest quality, and platinum experiments are the highest. Platinum-badged experiments have an associated power analysis, use a low alpha, limit the number of decision metrics, and utilize false discovery rate adjustment. Originally, experimenters were self-assigning badges based on shared Confluence documentation.
Self-badging did not guarantee the quality and trustworthiness of the experiment designs because experimenters constantly disregarded or misinterpreted guidelines to achieve the highest badge.
We integrated an automated badging system into the Hivemind platform to rectify this. Moving to an automated badging system allowed us to assess the quality of experiments across teams and organizational units, providing a transparent and accountable way to measure the rigor and integrity of our experimental practices. We also implemented leaderboards to help foster a culture of healthy competition by highlighting and incentivizing high-quality experimentation through leaderboards and promote excellence among teams.
The platform-enabled badging system also allows us to establish specific objectives and key results for running high-quality experiments. This is a substantial step forward as it provides measurable and trustworthy metrics that reflect our commitment to excellence in experimentation.
Having badging integrated within the platform also simplifies updating and communicating badging criteria. As we continue to evolve our understanding of best experimental practices, it's now seamless to inform and align hundreds of team members with the new standards.
Conclusion
In the evolving landscape of online services, GoDaddy has embraced the challenge of fostering a robust culture of experimentation. Through the dedicated efforts of our engineering and data science team and the strategic implementation of our Hivemind platform, we have not only standardized our experimentation process but also elevated the quality and reliability of our experiments.
Hivemind is more than an experimentation platform; it embodies our resolve to remain ahead of our competition and to help entrepreneurs grow online. By addressing and automating the categorization of metrics, streamlining analytical processes, and introducing a dynamic badging system, we have laid the foundation for a data-driven decision-making framework. The Hivemind platform’s focus has shifted from quantity to quality, where the merit of an experiment is not in its ability to produce significant results but in its capacity to yield genuine customer insights and drive real product innovation.





