
Key takeaways
- Prompt edits are code changes. Without automated testing, a single sentence rewrite can silently break agent behavior in ways nobody catches until the damage is done.
- Cosine similarity is the right scoring metric for LLM output because it measures whether the agent meant the same thing, not whether it used the same words.
- The system scales because the core engine is fully decoupled from agent-specific logic, so onboarding a new agent means dropping in a dataset and wiring a workflow without the need for a central team.
Here's a question that doesn't have a clean answer in traditional software engineering: how do you write a unit test for something that never returns the same value twice? This is the daily reality of building AI agents powered by Large Language Models, and it's a problem we kept running into until we built Veritas.
Your prompt is code. Start testing it like code.
A developer changes one line in a system prompt — maybe tightening a sentence, maybe clarifying how the agent should handle a specific case. The diff looks fine. The PR gets approved. Nobody catches anything.
For example, a prompt that previously read:
"Always confirm the user's domain before initiating any scan."
gets edited to:
"Initiate the scan and confirm the domain during the process."
One sentence. Sounds reasonable. But now the agent kicks off scans without confirming the domain first and something downstream that depended on that confirmation quietly breaks. A week later, someone notices things aren't working right and you're digging through commit history trying to figure out what changed. This isn't a careless mistake. The problem is that automated testing just doesn't work well for systems that are non-deterministic by design. That's what we built Veritas to fix.
The problem has two dimensions
At GoDaddy, we build multiple AI agents that help customers with tasks ranging from technical support to website configuration. Each agent is powered by LLMs and maintained by different development teams across the organization. This creates two problems — one obvious, the other less so.
The obvious one is when a developer edits a system prompt and accidentally makes things worse. Rewording instructions or removing an example might cause an agent to refuse valid requests or hallucinate product features. These changes are typically easy to spot because the changes to the system prompt change the output of the agent and the cause can be traced back to the diff.
The less visible one is model migration drift. When a team switches from GPT-4o to Claude Sonnet 3.5, that shift can affect agent behavior in ways completely invisible to a human reviewer even though the code diff exists. A slightly different tone. Subtle changes in how the agent handles ambiguous queries. These semantic shifts are exactly what Veritas is built to catch before they reach production. The fear of causing regressions was slowing developer velocity. No safety net meant teams hesitated to iterate on prompts or migrate models confidently. Slower iteration means slower AI improvements means slower feature delivery.
The breakthrough
Two responses don't need to use the same words to mean the same thing. Vector embeddings are numerical representations of complex, unstructured data (like words, sentences, or images) that capture context. Any piece of text can be turned into vector embeddings, and two sentences that mean the same thing produce numbers that are close to each other, even if the words are completely different. Veritas uses Amazon's Titan embedding model to generate these embeddings. Cosine similarity measures how close those numbers are — it's a metric that measures how similar two vectors are, regardless of their magnitude. Small angle means similar meaning, large angle means different meaning:
Cosine similarity = (A · B) / (||A|| × ||B||)
0.0 → completely different meaning
1.0 → semantically identicalLLMs naturally rephrase things — synonyms, restructured sentences, different filler words — while keeping the same meaning. Any metric that counts exact word matches penalizes that and fails responses that were actually correct. To confirm cosine was the right call, we tested it against Jaccard similarity, a simpler metric that just looks at which exact words two texts share (|A ∩ B| / |A ∪ B|). If two responses share lots of the same words, Jaccard scores them high. If they use different words to say the same thing, Jaccard scores them low.
The following image shows a test case where both responses were clearly saying the same thing:

A gap of 0.3844. Jaccard would have rejected a perfectly good response. Cosine correctly passed it. That settled it — cosine similarity is Veritas's primary scoring metric and the only thing that drives the pass/fail decision. The question we're asking isn't "did the bot say the same thing?" — it's "did the bot mean the same thing?"
End-to-end testing flow and trigger logic
Veritas fires in two scenarios: when a prompt file changes and when a model configuration changes. Both are tracked through code. A prompt change is visible in the diff directly and a model change can be detected via the variable that defines the model name. When that variable is updated, Veritas triggers automatically. The following diagram illustrates this trigger logic:
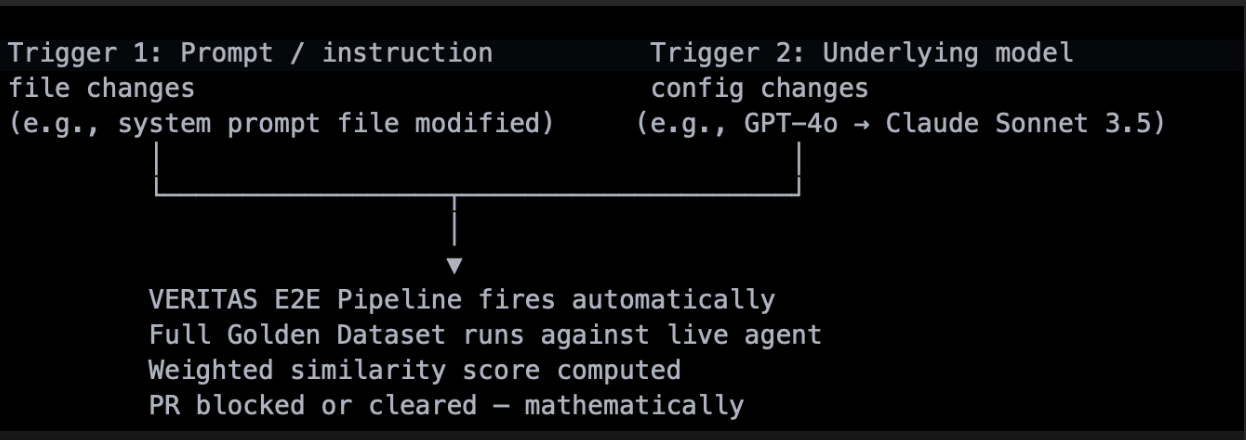
On trigger, Veritas runs as a GitHub Actions pipeline that deploys the agent to a dev environment and executes a full suite of multi-turn conversations against it. The following workflow diagram shows the complete pipeline:
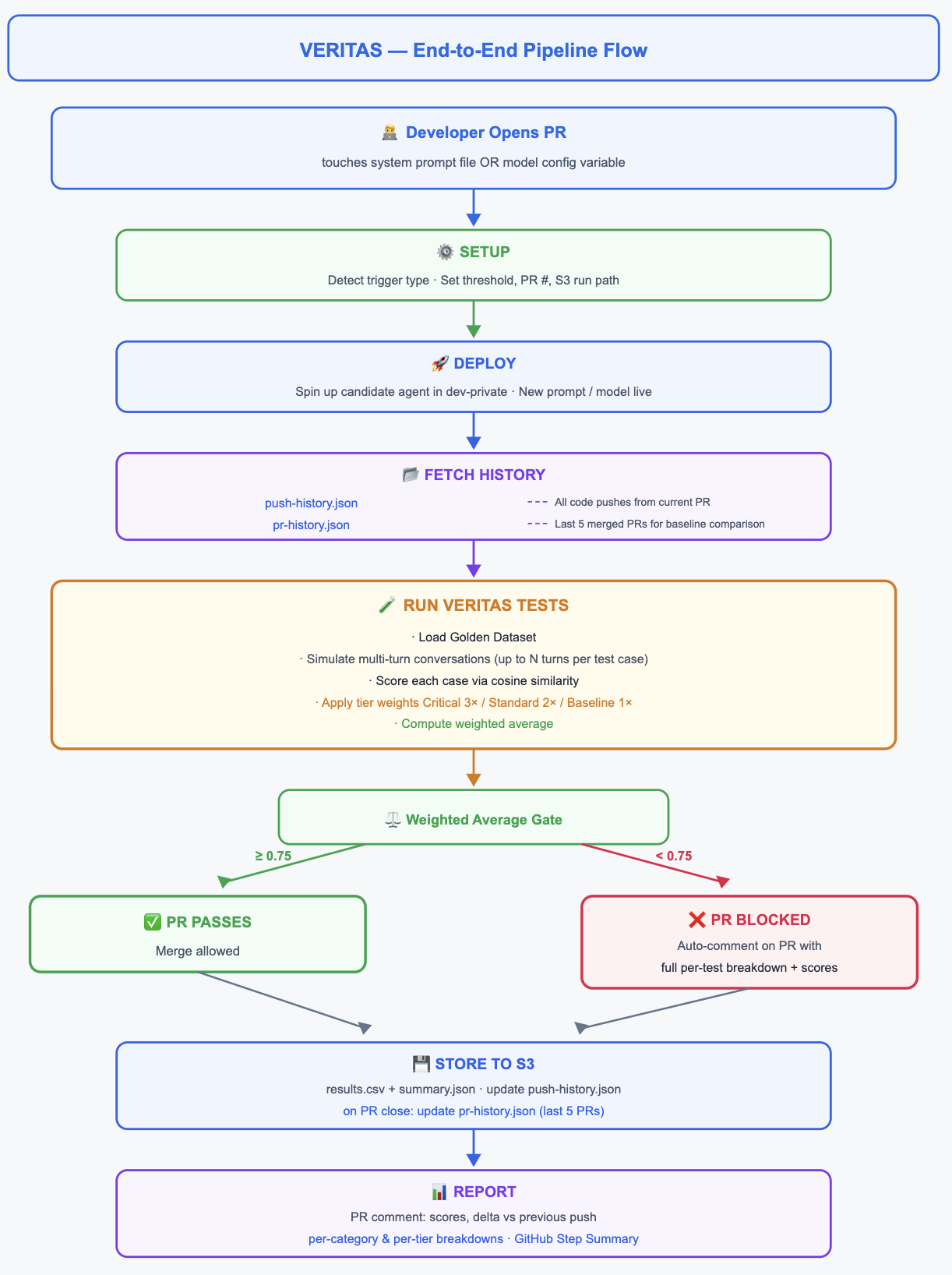
Three components that make the system work
The following sections describe the components of the Veritas system and how they operate.
The golden dataset — your agent's versioned definition of "good"
The Golden Dataset is a hand-curated JSON file in your agent's repository that captures what correct behavior looks like across the scenarios that matter. The following table shows the structure of the golden dataset:

What happens inside a single test
Here's exactly what happens for each Golden Dataset entry:
Turn 1: The prompt is sent to the live agent. The agent responds. That response and the ideal output from the dataset are both passed to the Titan embedding model, which converts them into vector embeddings. Cosine similarity is then calculated between the two vectors.
- Score above threshold → conversation stops, that score is the final result for this test
- Score below threshold → conversation continues
Turn 2 onwards: A lightweight LLM reads the agent's latest response and selects the most appropriate follow-up from a candidate list that becomes the next prompt sent to the agent. The agent responds, embeddings are generated, cosine similarity is calculated again.
This continues until either the score crosses the threshold or the conversation hits the turn limit (configurable per agent). If it reaches the limit without crossing the threshold, the highest cosine similarity score across all turns becomes the final result.
If there are N entries in the Golden Dataset, N tests run. After all are completed, Veritas calculates a final weighted average score — and that determines whether the PR passes or gets blocked.
The conversation strategy
After the agent responds, the system needs to decide what to say next to keep the conversation going. A two-layer system handles this. A lightweight LLM reads what the agent just said and picks the most appropriate follow-up from a candidate list. If the agent asked a clarifying question, the strategy answers it. If the agent completed a task, the strategy follows up the way a real user would. If the LLM call fails for any reason, a category-based fallback picks from a static list — but the pipeline never hard-stops. There's also a normalization step that expands abbreviations before scoring, so the agent isn't penalized for shorthand that carries the same meaning.
We chose this pattern because the alternative was firing generic follow-ups regardless of what the agent actually said. That produces robotic conversations that don't reflect how real users behave. Instead, the LLM actively reads the current state of the conversation and reasons about what a real user would most plausibly say next. The conversation adapts turn by turn rather than following a fixed path. The candidate list wasn't just written once and shipped. We ran real conversations, watched where the strategy produced follow-ups that felt off, and kept iterating until the simulated sessions were indistinguishable from real user interactions. Every team integrating something similar to Veritas should go through that same process with their own agent's conversation patterns — the candidate list is only as good as the calibration behind it.
The weighted scoring system
The weighted scoring system makes the tier distinction precise and automatic. The following diagram shows how the weighted average is calculated:
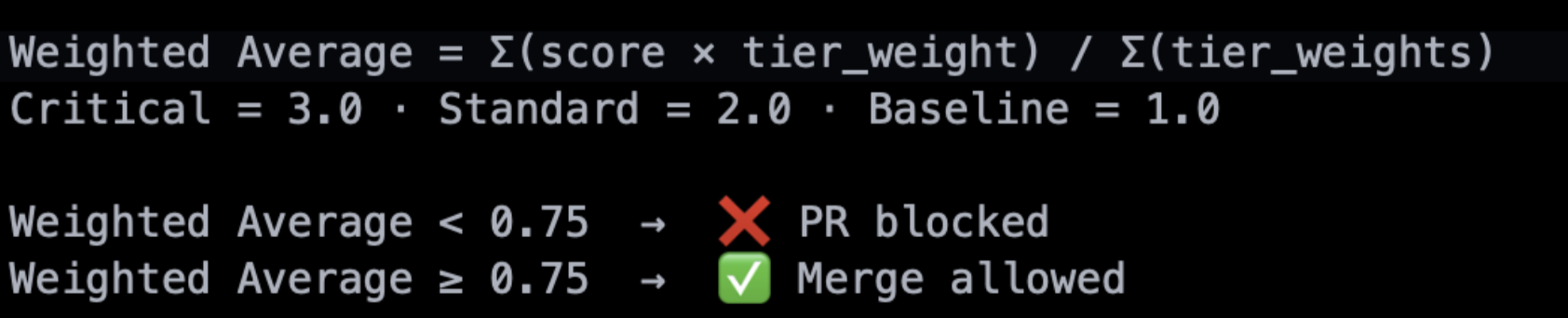
A 0.75 threshold on a weighted average is stricter than it looks. A single failing Critical test exerts three times the downward pressure of a failing baseline test — you cannot paper over a broken core flow with clean sanity checks. Early stopping is built in so after the threshold is met, the conversation ends, saving compute. The 0.75 threshold was calibrated for a specific use case — every agent that integrates a similar process should set its own threshold to reflect its quality bar.
The score history that pays off over time
Every run stores results.csv, summary.json, push-history.json per PR, and pr-history.json across the last five merged PRs. Questions like "did a critical flow regress when we switched models?" go from guesswork to a timestamped, queryable answer. In week one you catch individual regressions. After a few months you start seeing patterns across prompt changes and model migrations.
The reference integration — putting Veritas to the test
To make Veritas real, we needed a reference agent that would prove the system worked end-to-end. That agent was an AI-powered security product built to help website owners identify threats, scan their sites for malware, and walk through remediation steps conversationally. It doesn't just answer questions — it takes real actions: scanning live websites, detecting infections, and in remediation flows, cleaning up threats automatically. The failure modes were well understood, and the team needed confidence to iterate without fear of breaking live customer flows.
What was built: A Veritas-integration/ folder containing a hand-curated Golden_Dataset.json and conversation_strategy.py, plus a Veritas.yaml workflow triggering on changes to the agent's instruction file or model configuration variable.
What gets tested: Five categories of real customer interactions.
Configuration: 0.75 weighted average threshold · 5 max turns · tier weights Critical 3.0, Standard 2.0, Baseline 1.0.
The developer gets an automatic PR comment with a full per-test breakdown — category, tier, score, pass/fail, and a delta against the previous push. The PR cannot merge until the weighted average hits 0.75.
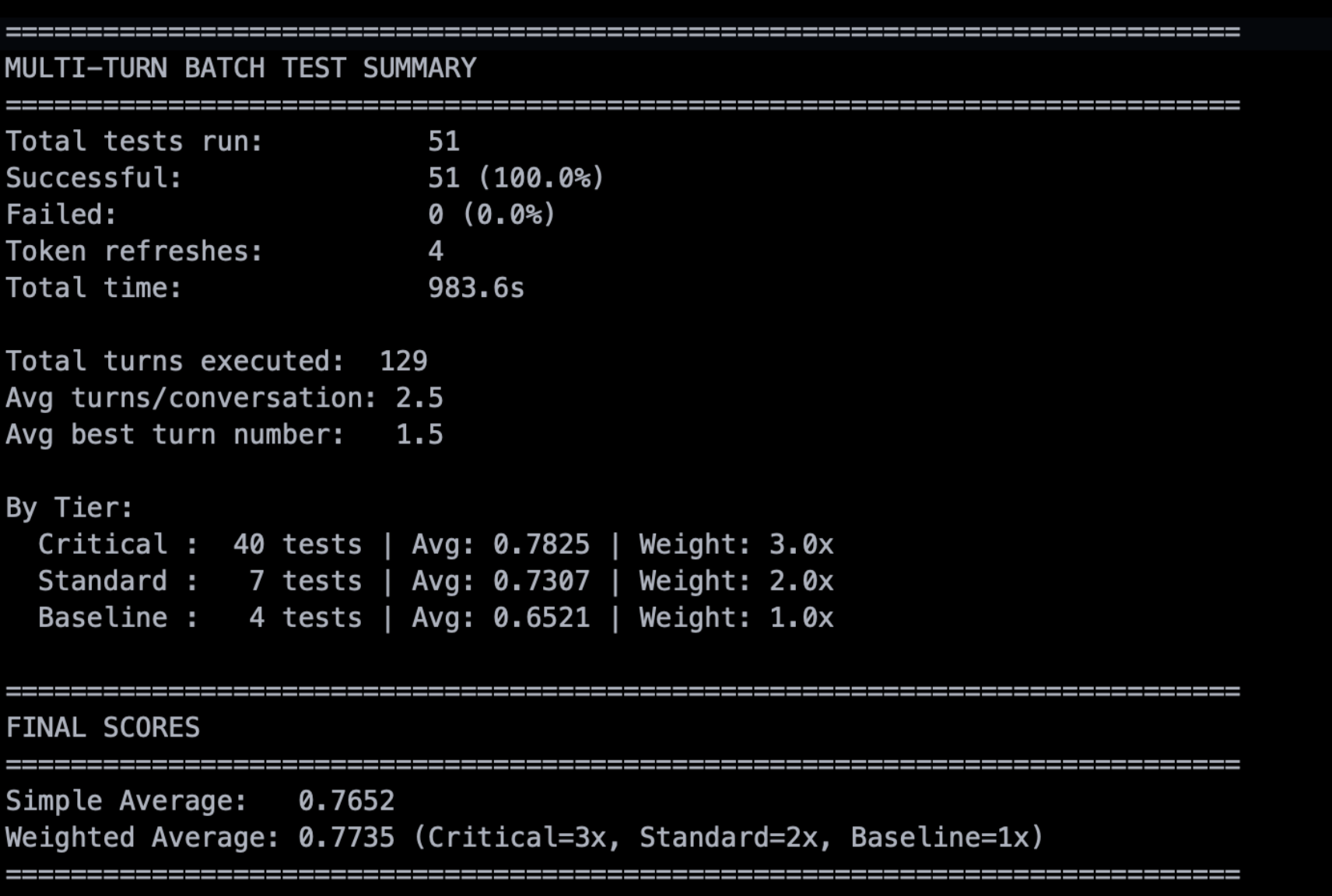
Every number is traceable and the pass decision is mathematical, not a gut feel. The following screenshot shows what results look like after all tests run:
Plug-and-play — built to scale across a fleet
The most important design decision was keeping the core engine completely separate from anything agent-specific. All the stuff that varies — golden dataset, conversation strategy, follow-up candidates, normalization rules — lives in the agent's own repository under Veritas-integration/. The core engine doesn't know anything about any specific agent. It just runs conversations, generates embeddings, computes scores, and applies weights. Onboarding means adding your dataset and conversation strategy and wiring up the workflow. No changes to the core engine. No back-and-forth with a central team. GoDaddy runs a growing fleet of AI agents — a solution that needs custom work per agent doesn't scale. One that ships as a template and runs inside each agent's own repo does.
The broader point
We put traditional code through static analysis, unit tests, and review gates before it ships because we've all seen what happens when you don't. AI systems have the same problem, just harder to spot. A prompt that scored 0.91 last month might score 0.71 today because someone swapped the underlying model. A change that passes a quick manual check might be silently failing the cases nobody thought to test.
Veritas is our answer to one specific question: how do you apply the same engineering discipline to AI behavior that you already apply to code? The answer is vector math, a carefully built dataset, and a GitHub Actions workflow. The math is not magic. The rigor is familiar. The only thing that changed is where we're pointing it.





