
Key takeaways
- Deep research requires iterative exploration: Treating AI research as an agentic process with planning, exploration, and synthesis phases enables systems to adapt to problem complexity rather than following fixed workflows.
- Structured evaluation transforms research quality into measurable metrics: Using LLM-as-judge methodology turns subjective research assessments into engineering feedback loops, enabling continuous improvement of agentic systems.
- Balancing autonomy with constraints enables production readiness: Configurable parameters for depth, breadth, and stopping criteria make agentic research predictable and scalable while maintaining adaptability.
Introduction
What happens when you ask an AI to do market research?
Most systems collapse the task into a single step: retrieve a few sources and generate a summary. That works for simple questions, but it breaks down when the problem is ambiguous. Market research requires deciding what to explore, identifying gaps in early findings, and iterating until the picture is coherent. The required depth isn’t known upfront.
Deep research is therefore iterative by nature, which makes it poorly suited to static workflows. Fixed pipelines either under-explore complex topics or waste effort on simple ones. At GoDaddy, we ran into this limitation while trying to automate market research at scale.
The solution was to treat research as an agentic process.
In this post, we introduce the Market Deep Research Agent, an AI system that plans and executes multi-step research loops. Given a topic, the agent generates targeted queries, evaluates ambiguity in intermediate results, and decides when to go deeper or stop. Its behavior is bounded by configurable defaults for depth, breadth, and iteration limits, allowing us to balance research quality against latency and cost. The Market Deep Research Agent is available to GoDaddy customers as part of our business and marketing tools.
We’ll walk through the core methodology behind deep research agents, outline the three-phase research pipeline we use in production, and conclude with the evaluation approach we use to measure research quality and consistency. The goal is not just faster answers, but a reliable, tunable system for producing deep, structured research at scale.
Market research as a multi-dimensional system
Market research is not a single question, but a collection of related investigations. Understanding competitors, customers, market conditions, and external forces each requires different sources, search strategies, and analytical frameworks. While these dimensions inform one another, they cannot be treated interchangeably.
The following table describes the different research dimensions and their key components:
| Research Dimension | Key Components |
|---|---|
| Company Analysis | Strengths, weaknesses, strategic differentiators |
| Target Customers | Demographics, psychological profiles, buying behaviors |
| Competitor Landscape | Market positioning, strategies, competitive advantages |
| Market Climate | Economic, technological, and industry trends |
| Regulatory Factors | Legal considerations and sociocultural trends |
In practice, teams need dedicated, well-scoped outputs for each dimension — not a single blended summary. When research is done manually, producing this level of coverage takes significant time. When attempted with a single LLM prompt, the result is often uneven: some sections are overdeveloped, others are shallow, and critical dimensions may be skipped entirely. The structure of the research is left implicit, and coverage becomes inconsistent.
This makes market research fundamentally a structural problem: each dimension must be explored independently, to an appropriate depth, before the results can be meaningfully combined.
From static queries to agentic research
Addressing this problem required more than better prompts. We needed a system that could reason explicitly about research structure and adapt its behavior as investigation progressed.
Our solution is an agentic research system built around a single coordinating agent and a set of specialized research tools. The system intentionally uses different LLMs at different stages of the workflow: a lightweight model (GPT-4o mini) is used for high-volume tasks such as query generation and search exploration, while a more capable model (GPT-4o, at the time of development) is reserved for deeper reasoning and final report generation. Asynchronous task orchestration allows these stages to run efficiently while preserving overall research coherence.
Rather than relying on a single query or monolithic generation step, the agent decomposes research into explicit dimensions and manages them independently. Each dimension follows its own search path and depth, ensuring balanced coverage and preventing overemphasis on any single area.
As results come in, the agent evaluates uncertainty and generates targeted follow-up queries where gaps remain. Research across dimensions runs in parallel and is only synthesized once each section reaches sufficient depth. The outcome is a structured, actionable report whose balance and quality are the result of deliberate control, not emergent behavior.
A three-phase research pipeline
To balance research depth, latency, and cost, we structure the system as a three-phase pipeline. Each phase maps to a distinct responsibility in the agent’s control loop: planning, exploration, and synthesis. This separation allows us to tune performance characteristics independently while keeping the overall system predictable and observable.
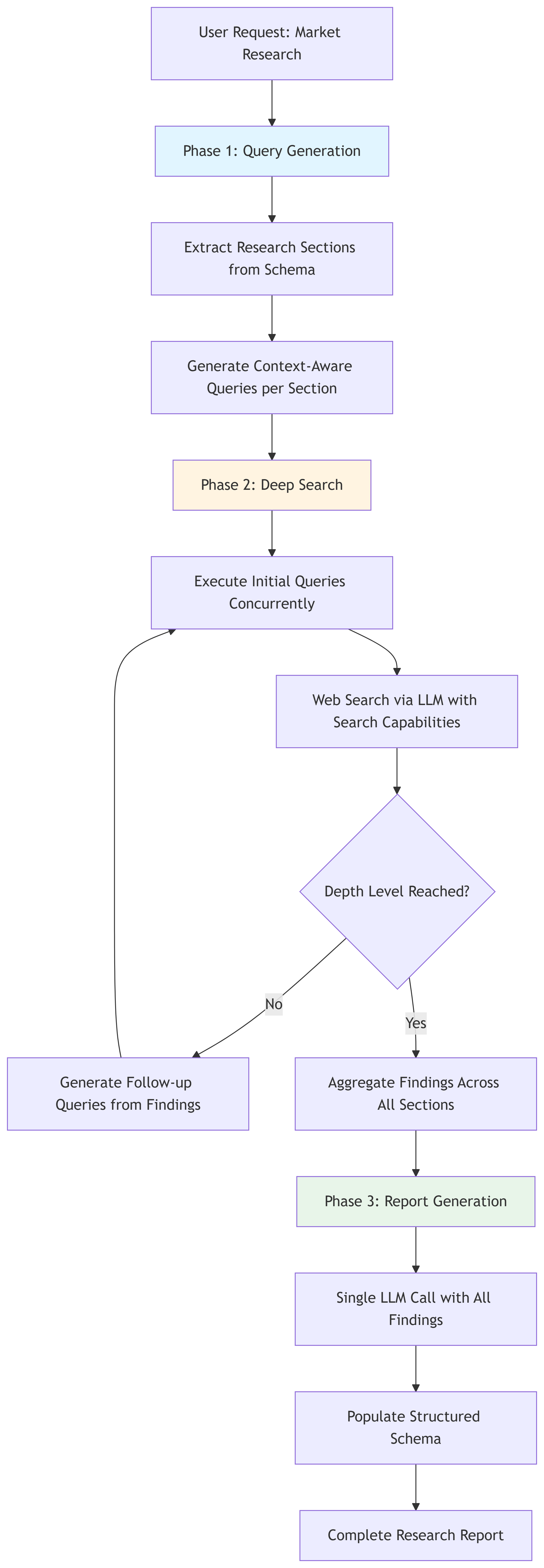
Phase 1: Query generation (planning)
The pipeline begins by extracting research sections directly from a predefined schema. Each section represents an explicit research objective rather than an implicit prompt instruction. For each section, the agent generates context-aware search queries using an LLM, conditioned on business metadata such as industry, geography, and business goals.
This phase corresponds to the planning step in deep research agents: the agent decides what questions must be answered before retrieval begins, instead of relying on a single, monolithic query.
All query generation runs concurrently using asynchronous execution, allowing the system to fan out early without introducing unnecessary latency. For example, let's say you own a craft beer shop and you want to explore expanding your online presence. You might ask the agent something like:
"Provide me with a market analysis of online craft beer vendors."
The agent would generate separate query sets for competitors, customer segments, market trends, and regulatory constraints, each scoped to its own research dimension. For instance, it might produce queries such as:
- Competitor landscape: "top direct-to-consumer craft beer brands 2024," "craft beer e-commerce market share"
- Target customers: "online craft beer buyer demographics," "craft beer subscription box trends"
- Market climate: "craft beer e-commerce growth rate," "DTC alcohol shipping regulations by state"
Each dimension gets its own set of context-aware queries; the agent does not collapse everything into a single search. The eventual response would be a structured report with clearly separated sections (competitors, customers, market signals, regulatory factors) rather than one long narrative—so you can assess feasibility and next steps without digging through a blended summary.
Phase 2: Deep search (iterative exploration)
Search execution follows an iterative deepening strategy. Initial queries are executed concurrently using an LLM with web search capabilities. Results are analyzed independently per research dimension to assess coverage, signal strength, and remaining ambiguity.
When gaps or uncertainty remain, the agent generates follow-up queries targeted only at the affected dimension. This loop continues until predefined stopping criteria are met.
The following table describes the different stopping criteria:
| Parameter | Purpose |
|---|---|
| Depth level | Controls how many refinement rounds the agent can run |
| Breadth per level | Limits the number of parallel queries per iteration |
| Follow-up strategy | Expands search based on evidence gaps or ambiguity |
Each depth level waits only for the current batch of searches to complete before proceeding, which keeps execution bounded. Findings are aggregated incrementally within each section, preventing early signals from one area from biasing others.
Sticking with the beer shop example: after the first round of searches, the agent might see strong, coherent results for target customers and regulatory factors (e.g., clear demographics and state-by-state shipping rules) and leave those sections as-is. For competitors, however, the initial results might note both regional breweries and national players but leave the differentiation vague ("sources mention regional vs. national craft brands but disagree on pricing and shipping models"). The agent then issues follow-up queries only for the competitor dimension, for example:
- "craft beer DTC pricing comparison regional vs national brands"
- "alcohol direct shipping policies by retailer type 2024"
Customer and regulatory searches are not re-run; only the competitor section gets a second batch. Once those follow-up results are in, the competitor section is updated and the pipeline can proceed. That way each dimension is refined to the right depth without wasting queries on sections that are already sufficient.
Depth and breadth defaults are chosen to balance exploration quality with predictable performance. Initial values are set conservatively based on empirical evaluation across common research scenarios, then adjusted dynamically within bounded limits. For well-defined topics with high-confidence signals, the agent converges quickly and stops early. For ambiguous or conflicting findings, additional iterations are allowed up to the configured depth and breadth ceilings. This approach lets the agent adapt to problem complexity while keeping latency and cost under control.
Phase 3: Report generation (synthesis)
After all research sections reach sufficient depth, the system performs a single synthesis call. All findings are passed to the LLM in a structured, schema-aligned format. At this stage, the model’s role shifts from discovery to consolidation.
The LLM compresses section-level evidence into a coherent report while preserving boundaries between research dimensions. This produces balanced coverage and makes the output easier to review, validate, and reuse.
For the beer shop, the final report is not one long narrative but a structured deliverable with clearly separated sections. For example, the agent might return something like:
Competitor positioning
Key DTC craft beer players include regional breweries (e.g., local taproom-to-door) and national brands (e.g., subscription boxes). Regional players often compete on freshness and local loyalty; national players on selection and convenience. Pricing and shipping policies vary by state and retailer type—direct shipping rules are a major differentiator.
Target customers
Online craft beer buyers skew 25–44, with strong overlap in subscription and “discovery” purchasing. Growth is driven by e-commerce adoption and interest in small-batch and local brands.
Market signals
Craft e-commerce continues to grow post-pandemic; DTC and third-party marketplaces both expanding. State regulatory changes are shifting what’s possible for direct shipping.
Regulatory factors
Alcohol direct shipping is state-by-state; many states allow DTC from licensed producers with volume limits. Retailer-to-consumer shipping remains more restricted. Compliance (age verification, tax) is required.
Each section stays scoped to its dimension, so the business can assess feasibility and next steps (e.g., “Can we ship to our target states?” or “How do we differentiate from national subscription brands?”) without digging through a blended narrative.
The result is a structured research artifact that is bounded in scope, consistent in format, and ready for downstream decision-making.
The following chart illustrates the Market Research Agent workflow:
Engineering challenges and what we learned
Building a deep research agent surfaced challenges that are common to long-horizon, agentic systems — but it also forced us to confront an important design tension: how much autonomy an agent should have versus how much structure a workflow should impose.
The following table summarizes the major challenges we encountered and the architectural decisions that addressed them:
| Challenge | Design Choice | Result |
|---|---|---|
| Multi-step planning | Schema-driven decomposition with explicit research dimensions | Ensures balanced coverage and avoids unstructured exploration |
| Unbounded iteration | Configurable defaults for depth, breadth, and stop conditions | Agent runs enough iterations without runaway cost or latency |
| Long-running inference | Asynchronous task orchestration with shared state | Partial failures don’t derail the entire research process |
| Context growth | Controlled aggregation and section-level state | Maintains continuity without overwhelming the model |
| Parallel execution | Fully asynchronous query generation and search | Reduces end-to-end latency while preserving depth |
| Error propagation | Fail-fast checks and moderation gates | Prevents low-quality signals from compounding downstream |
A key takeaway is that reliable research systems are not built by optimizing individual model calls in isolation. They are built by shaping the flow around those calls — making planning explicit, iteration bounded, and synthesis deliberate. Defaults matter: well-chosen parameters allow an agent to behave intelligently without requiring constant human tuning, while still making performance characteristics observable and controllable.
This framing also clarifies when to use an agent versus a fixed workflow. Workflows excel when the problem is well-defined and depth is known upfront. Agents are necessary when uncertainty exists and the system must decide how much exploration is enough. By combining agentic decision-making with workflow-level constraints, we get the best of both: adaptability without unpredictability.
Evaluation: measuring research as an engineering system
Building a deep research agent is only half the problem. The other half is knowing whether it is actually doing good research — and doing so in a way that supports iteration.
Research quality does not have a single ground truth. Usefulness depends on context, structure, depth, and coverage, not just factual correctness. To make progress measurable, we treated evaluation itself as an engineering problem and adopted a multi-metric, LLM-as-judge approach—using LLMs themselves to evaluate the quality of AI-generated research outputs against structured rubrics.
At a high level, each evaluation run takes four inputs:
- The conversation transcript, capturing what the user asked for and how the agent responded
- The final deliverable, representing the completed research output
- The business context, including the initial inputs and goals
- The scenario type, defining the expected shape of the research outcome
From these inputs, we run multiple independent judges in parallel. Each judge evaluates a specific metric on a 1 to 5 scale and provides written reasoning and supporting notes. The results are consolidated into a single evaluation artifact.
What we measure
Evaluation signals are grouped into five categories, each capturing a different dimension of research quality or system behavior. The following table describes the metrics analyzed and purpose of each evaluation signal:
| Category | Metrics Covered | Purpose |
|---|---|---|
| Response Quality | Relevance, accuracy, completeness, depth | Validates that the research addresses the request, is grounded in context, and contains actionable insight |
| Conversation Flow | Task completion, efficiency, context retention, coherence | Ensures the agent progresses logically without unnecessary turns or contradictions |
| Business-Specific Performance | Research quality for the domain, tool usage effectiveness | Grounds evaluation in real-world applicability and correct artifact generation |
| User Experience | Satisfaction signals, professionalism, clarity | Measures whether outputs are usable and easy to iterate on |
| Technical Performance | Typical and worst-case latency, derived performance score | Keeps the system predictable and production-ready |
Each metric is scored on the following 1 to 5 scale:
- 1 indicates a clear failure (missing, incorrect, or unusable)
- 3 represents an acceptable baseline that meets expectations
- 5 reflects strong performance with clear evidence of depth and quality
In practice, most actionable feedback lives in the 2 to 4 range. Scores in this band indicate that the research is usable but reveals specific weaknesses — most commonly insufficient depth, excessive breadth, or premature stopping.
This evaluation loop directly informs how we set and tune agent defaults. In this way, evaluation acts as the feedback mechanism that balances agent autonomy with workflow-level performance constraints.
Aggregation and outputs
Each evaluation produces:
- an overall score computed as the average across all metrics.
- a timestamp and total evaluation runtime.
- per-metric reasoning notes for diagnosis.
Results are persisted and compared over time across agent versions, scenarios, and business profiles. This allows us to track whether changes to planning logic, depth limits, or stopping criteria meaningfully improve research quality without sacrificing performance.
Results and impact
This evaluation framework allowed us to treat the research agent as an engineering system rather than a collection of subjective outputs. By grounding feedback in consistent metrics, we created a tight loop between agent behavior, parameter tuning, and observable outcomes.
In practice, this enabled us to:
- compare agent changes against a stable rubric covering research quality, flow, business relevance, and user experience.
- diagnose failure modes quickly, such as distinguishing insufficient depth from factual inconsistency, which require different fixes.
- track quality trends over time across multiple scenarios and business profiles.
Even without a single ground truth, the framework kept the agent focused on producing research that is structured, actionable, and appropriate for the problem at hand.
Key outcomes included:
- predictable personalization, with research tailored to specific businesses and markets
- balanced coverage across core research dimensions rather than emergent, uneven summaries
- explicit quality gates, where LLM-judged scores with reasoning turn subjective assessments into debuggable signals
- faster iteration cycles, supported by parallel evaluation and clear performance tradeoffs
- reusable outputs, enabled by schema-driven structure that simplifies review and comparison
Limitations and future work
While the Market Deep Research Agent performs well for exploratory market analysis and structured synthesis, it is less effective for domains that require proprietary data access, real-time signals, or deep quantitative modeling. Some challenges remain open, including handling conflicting sources at scale, improving confidence calibration for ambiguous findings, and extending the system to support longitudinal or continuously updating research. Future work includes experimenting with richer tool feedback loops, tighter integration with internal data sources, and adaptive stopping criteria that learn from past evaluations. We see this system as an evolving research collaborator rather than a finished product.
Conclusion
Deep market research cannot be reduced to a single prompt or static workflow. It requires planning, iteration, and controlled exploration under uncertainty. The Market Deep Research Agent puts this into practice by treating research as an agentic process: generating targeted queries, iterating through deep search, and synthesizing findings into structured outputs.
Just as importantly, we treated evaluation as a first-class system component. By measuring research quality across content, flow, business usefulness, and performance, we can tune agent behavior deliberately and keep the system reliable as requirements evolve. The result is not just faster research, but a measurable and continuously improving approach to AI-driven analysis.





