
Introduction
At GoDaddy, we are a data-driven company that relentlessly pursues valuable insights through our various data streams and pipelines. It’s imperative these data pipelines and streams can fit the needs of our data producers and consumers so we can continue to fuel our business decisions and values.
However, the problem comes when we lack sufficient test data to drive and test our data pipelines before reaching production. Testing data pipelines without production data is slow, laborious, and risky — and copying production data into lower environments isn’t an option for privacy and security concerns. To give teams realistic inputs without the risks of production data or the labor of creating or maintaining test data, we’re building a cloud‑native synthetic data generator with AWS that turns data schemas into production-like datasets through an API call. This post shares why we built it, the architecture, and what we hope to see where this data generator improves in the future.
Understanding synthetic data
Before diving into our specific challenges, let's establish what synthetic data is and why it matters for modern data engineering. Synthetic data is artificially generated information that mimics the statistical properties, patterns, and relationships of real production data without containing any actual sensitive information. Think of it as creating a realistic stunt double for your production data — it looks and behaves similarly but isn't the real thing.
How synthetic data compares to production data
While production data is the gold standard for accuracy, synthetic data offers several advantages:
Privacy and compliance: Synthetic data contains no PII, making it safe for development and testing environments. This is crucial for companies handling sensitive customer information.
Scalability: Need a billion records for load testing? Synthetic data can be generated on demand without waiting for organic growth.
Edge case coverage: Production data might lack certain scenarios. Synthetic data can deliberately include rare events, error conditions, or future-state scenarios.
However, synthetic data also has limitations:
Realism gaps: Even the best synthetic data may miss subtle patterns or correlations present in production data. Real-world data often contains "messiness" that's hard to replicate — typos, incomplete records, or unexpected relationships.
Domain knowledge requirements: Generating realistic synthetic data requires deep understanding of the business domain, data relationships, and constraints.
Validation challenges: How do you know if your synthetic data is "good enough"? This remains one of the hardest problems in the field.
Challenges with test data at GoDaddy
Currently, within our data lake platform, data producers and consumers face challenges in generating and utilizing realistic test data that closely mirrors production data. Producers and consumers oftentimes resort to registering production data and engage in iterative troubleshooting cycles until achieving successful integration. This results in hesitancy, unfamiliarity, and increased security risks when real production data is used in lower environments such as development, testing, and staging.
On the other hand, manually creating realistic test data is time-consuming and requires significant engineering overhead effort for both initial setup and ongoing maintenance. Especially when tens to hundreds of schemas are expected to be created and maintained; this expectation doesn’t scale.
Why existing solutions fell short
Before building our own solution, we evaluated several approaches that each had significant drawbacks:
Manual test data creation: Engineers were spending days crafting JSON files and SQL scripts. This approach couldn't scale to our hundreds of schemas and millions of records.
Production data sampling: Copying and anonymizing production data seemed attractive but introduced security risks, compliance nightmares, and couldn't generate future-state scenarios.
Off-the-shelf generators: Tools like Faker and Mockaroo work well for simple schemas but struggled with our complex relationships, custom constraints, and GoDaddy-specific business logic.
Pure LLM generation: We experimented with having LLMs generate entire datasets directly. While the quality was impressive, the cost and latency of generating millions of rows made this approach impractical. For example, generating one million customer records would cost thousands of dollars and take days to complete.
Each failed approach taught us something valuable: we needed a solution that combined the intelligence of LLMs with the scale of traditional data generation tools.
Solution overview
Our breakthrough came from realizing we didn't need an LLM to generate every row — we needed it to understand the schema and create intelligent generation templates. We built a cloud-native synthetic data platform that combines:
Databricks Labs Datagen: A proven library for generating data at scale, but typically requires manual template creation.
GoCode (our LLM API): Analyzes schemas and automatically generates sophisticated Datagen templates with realistic distributions, constraints, and relationships.
EMR Serverless: Provides the distributed compute needed to generate billions of rows efficiently.
This hybrid approach gives us:
- Intelligence at template time: LLMs understand business context and create realistic generation rules once, not for every row.
- Scale at runtime: Datagen and EMR handle the heavy lifting of generating millions of records from those templates.
- Cost efficiency: We pay LLM costs once per schema, not per row — a 99.9% cost reduction compared to pure LLM generation.
- Domain awareness: The LLM can infer realistic patterns from column names and constraints (e.g.,
emailfields get valid email formats,phone_numberfollows regional patterns).
The solution's primary focus is supporting producers who want to validate their data pipelines using synthetic data and use other platform’s tools such as DeX (data excellence – our tool to ensure data quality within our pipelines), to ensure that their pipeline will run well in a lower environment before releasing to production. Consumers of this synthetic data will be able to consume it, from the lake’s test environment, for their internal data pipelines or integration. We look to catch problems early before they reach production, eliminate security concerns with automated testing, and reduce engineering hours spent on data creation.
Challenges we overcame
Building this system wasn't straightforward. Here are the key challenges we faced and how we solved them:
Challenge 1: Lambda timeout limitations
Our initial prototype used Lambda functions to generate data. This worked for small datasets but hit the 15-minute timeout limit when generating millions of rows.
Solution: We pivoted to EMR Serverless, which can run for hours and scale horizontally. This required rewriting our generation logic in Spark but gave us virtually unlimited scale.
Challenge 2: LLM hallucinations in templates
Early versions sometimes generated templates with syntax errors or impossible constraints (e.g., ages ranging from -10 to 300).
Solution: We implemented a validation layer that checks generated templates against schema constraints and a library of known-good patterns. Invalid templates are regenerated with more specific prompts.
Challenge 3: Cross-account S3 permissions
Writing generated data to producer-owned S3 buckets across AWS accounts introduced complex permission challenges.
Solution: We implemented a flexible permission model supporting both bucket policies and assumed roles, allowing producers to choose their preferred security approach.
Challenge 4: Cost optimization
Running EMR clusters for every generation request would be expensive.
Solution: We adopted EMR Serverless with intelligent job batching, reducing costs by 80% compared to always-on clusters.
Technical deep dive: How each component works
Let's explore the inner workings of each major component in our synthetic data generation system. Understanding how these pieces work together helps explain why this architecture delivers both intelligence and scale.
GoCode template generation
When a schema is submitted, GoCode doesn't just look at data types — it understands semantic meaning:
// Input schema
{
"customer_id": "string",
"email": "string",
"age": "integer",
"registration_date": "timestamp",
"country": "string"
}
// GoCode generates Datagen template
{
"customer_id": {"type": "uuid"},
"email": {"type": "email", "domain": ["gmail.com", "yahoo.com", "godaddy.com"]},
"age": {"type": "integer", "distribution": "normal", "mean": 35, "stddev": 12, "min": 18, "max": 95},
"registration_date": {"type": "timestamp", "start": "2020-01-01", "end": "now"},
"country": {"type": "weighted_choice", "weights": {"US": 0.4, "UK": 0.2, "CA": 0.15, "AU": 0.1, "other": 0.15}}
}The LLM infers realistic distributions, understands that emails need valid formats, and creates weighted distributions for categorical data based on typical patterns.
EMR Serverless execution
Our Spark jobs are optimized for synthetic data generation:
- Partitioned generation: Data is generated in parallel across partitions for maximum throughput
- Memory-efficient streaming: We use Spark's structured streaming to generate data without loading entire datasets into memory
- Smart batching: Multiple small requests are batched into single EMR jobs to reduce overhead
Quality validation
Generated data goes through multiple validation steps:
- Schema compliance: Ensures all required fields are present with correct types
- Constraint validation: Checks unique constraints, foreign keys, and custom rules
- Statistical validation: Compares distributions against expected patterns
- Referential integrity: Ensures relationships between tables are maintained
Design of data generator
A producer or consumer registers a schema with the data lake. The system stores metadata, orchestrates a data-generation workflow, renders GoCode-based templates into executable code, runs on EMR to synthesize data, and writes Parquet files to the producer’s S3 bucket. Status is tracked throughout in DynamoDB and surfaced via the DLMS (our data lake management service) API.
The following diagram illustrates how data flows through our synthetic data generation system, from initial schema registration through final Parquet output:
The following architecture diagram shows the flow from schema registration to synthetic data generation:
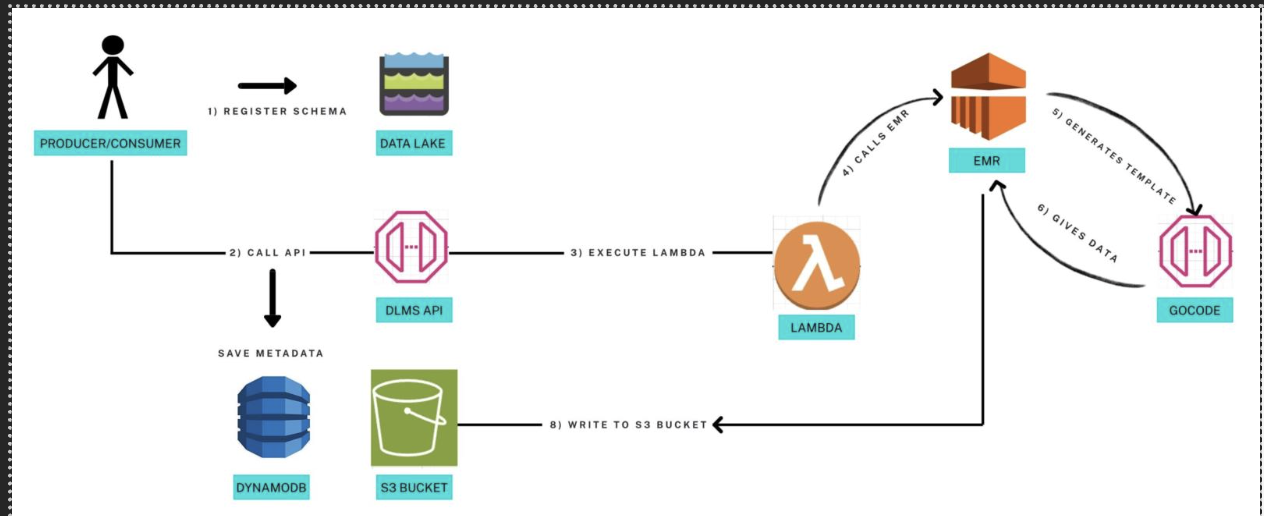
The process involves several key phases: Registration and validation where schemas are submitted and validated, template generation where GoCode creates intelligent generation templates, distributed processing where EMR Spark clusters generate data at scale, and secure delivery where results are written directly to producer-owned S3 buckets.
The following sequence diagram shows a more detailed view of the interactions between components and the step-by-step flow:
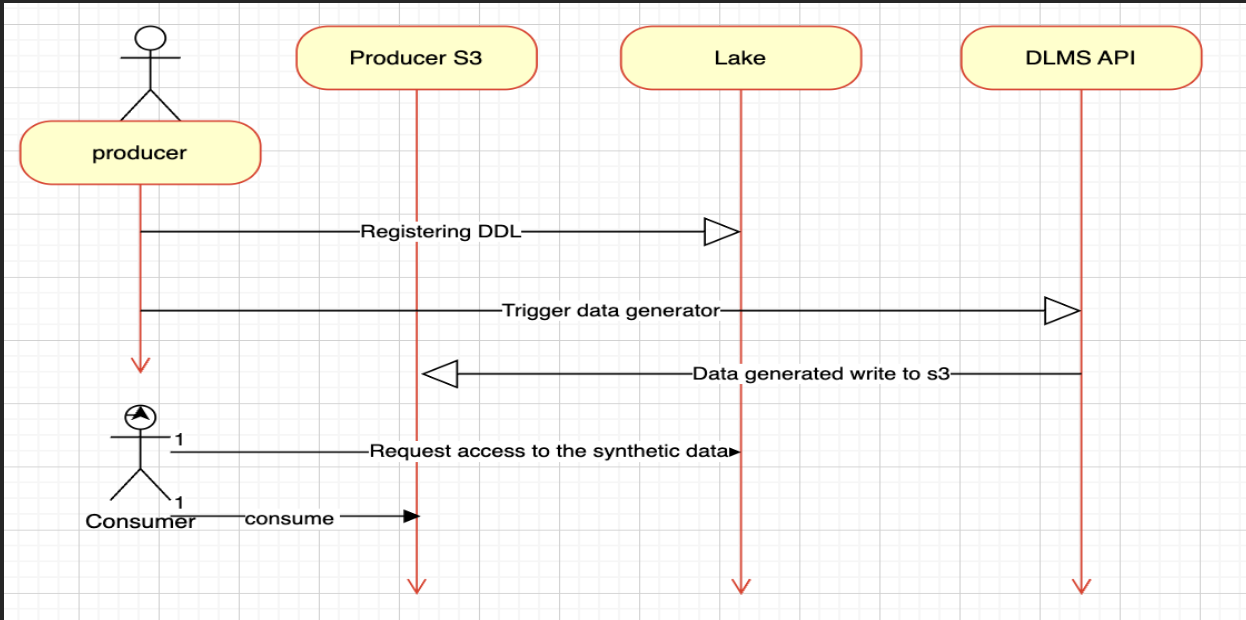
End-to-end flow
The synthetic data generation process follows a carefully orchestrated workflow that ensures data integrity, security, and scalability at every step. From the moment a schema is submitted to when synthetic data lands in the producer's S3 bucket, each component plays a critical role in delivering production-quality test data. Let's walk through how a typical data generation request flows through our system:
- Producer or consumer submits schema: via Data Lake API. Payload includes schema definition, dataset name, target bucket/path, and generation parameters (row count, partitions, date range).
- Persist and track: Data Lake API writes a new record to DynamoDB: schema, owner, target S3, desired state, and an initial status (e.g., SUBMITTED).
- Orchestrate generation:DLMS API is invoked to start a generation workflow for that schema/version. It acts as an orchestrator (auth, validation, idempotency, retries).
- Trigger compute: DLMS calls a Lambda that constructs the job spec (schema reference, template, Spark parameters) and submits it to EMR (on-demand or via EMR Serverless).
- Generate code template: Within the workflow, a GoCode template engine renders a strongly typed data model and generation logic from the schema (e.g., field types, constraints, distributions, PK/FK rules). Output is compiled or packaged for Spark execution.
- Execute on EMR: Spark job (EMR) uses the generated code to synthesize realistic, schema-conformant records at scale (partitioning, skew handling, nullability, referential integrity). Data is serialized to Parquet with proper compression and column types.
- Write to S3 (producer bucket): Output is written to the producer’s designated S3 prefix (e.g.,
s3://producer-bucket/datasets/<name>/dt=YYYY-MM-DD/). Cross-account write is permitted via bucket policy or an assumed role (depending on org policy). - Update status: On success or failure, the workflow updates DynamoDB (
RUNNING → SUCCEEDED/FAILED) and exposes status via DLMS API for UI/automation polling.
Why this architecture?
We chose this architecture for several key reasons that address both technical and operational challenges:
Scalability was paramount. EMR and Spark can handle billions of rows through intelligent partitioning and autoscaling, ensuring our solution grows with GoDaddy's data needs. This eliminates the bottlenecks we'd face with traditional data generation approaches.
Type safety and performance matter. Our Go-based template generation ensures compile-time correctness and delivers better runtime performance compared to interpreted alternatives. This catches errors early and keeps generation speeds high.
Security follows GoDaddy's best practices. Producers maintain ownership of their buckets, with access granted through bucket policies or assumed roles rather than long-lived credentials. This aligns with our zero-trust security model.
Observability is built-in. Every job is tracked in DynamoDB with comprehensive metadata: timestamps, row counts, output paths, and detailed error messages. This visibility is crucial for debugging and monitoring at scale.
Idempotency prevents costly mistakes. Job keys derived from schema ID, version, date, and partition prevent duplicate runs, protecting against both accidental re-execution and wasted compute resources.
Lessons learned and practical takeaways
After six months of development and early production use, here's what we've learned:
For engineers building similar systems
Start with the hybrid approach: Pure LLM generation seems attractive but doesn't scale. Traditional generators lack intelligence. The hybrid approach gives you the best of both worlds.
Invest in validation early: Bad synthetic data is worse than no data. Build robust validation into your pipeline from day one.
Make it self-service: The biggest adoption barrier is complexity. Our API-first approach means teams can generate data without understanding the underlying complexity.
Plan for evolution: Schemas change. Build versioning and backwards compatibility into your system from the start.
For teams using synthetic data
Synthetic data has limits: It's great for functional testing and development but may not catch all production edge cases. Use it as one tool in your testing arsenal.
Validate with production patterns: Periodically compare your synthetic data distributions with production patterns to ensure realism.
Start small, scale gradually: Begin with simple schemas and gradually add complexity as you build confidence in the system.
Real-world impact
Since launching, we've seen:
- 90% reduction in time spent creating test data
- 100% elimination of production data in test environments
- 5x faster pipeline development cycles
What makes our approach unique
While synthetic data generation isn't new, our approach offers several innovations:
- LLM-powered intelligence without LLM-scale costs: Using LLMs for template generation, not data generation, gives us intelligence at a fraction of the cost.
- Domain-aware generation: The system understands business context, not just data types, creating more realistic data.
- Truly scalable architecture: EMR Serverless provides virtually unlimited scale without infrastructure management.
- Self-service API: Teams can generate data with a simple API call, no synthetic data expertise required.
Summary and next steps
In building our cloud-native synthetic data generator, we’ve laid the groundwork for safer, faster testing of upcoming services at GoDaddy, without relying on sensitive production data. While the tool is newly completed and still in the early stages of adoption, its architecture and the lessons learned throughout development showcase a creative and scalable solution to a common industry challenge. From navigating AWS services for the first time to shifting from Lambda to EMR for efficient Spark execution, this project pushed us to solve real engineering problems in real time and at scale.
Building this system taught us that the real challenge isn't generating fake data — it's generating realistic fake data at scale. By combining LLM intelligence with traditional data generation tools, we've created a system that gives teams the best of both worlds: intelligent, context-aware data generation at a cost and scale that actually works for enterprise use. We’re excited for what’s next: smarter, more context-aware synthetic data powered by tools like MCP, and eventually, the possibility of open-sourcing this solution for teams beyond GoDaddy.
Thanks to our 2025 Summer interns Benson Doan, Anwita Kamath, and Yousuf Al-Bassyioni for helping to work on this solution!





