
Key takeaways
- Effective LLM evaluation starts by connecting business outcomes directly to test data through golden datasets, not treating testing as an afterthought.
- Modern LLM testing requires both traditional ML metrics (precision, recall) and newer approaches like LLM-as-a-judge patterns that localize and categorize specific errors.
- Transform evaluation from manual spot-checks into automated CI/CD pipeline integration with feedback loops that continuously expand golden datasets and refine system performance.
Would you put a brand-new car on the road without testing its brakes? Of course not. Yet in the rush to deploy AI agents or LLM workflows, many teams release LLM-powered applications without rigorous evaluation.
From chat bots to marketing assistants to image and website generators — LLM adoption remains explosive. But how well you test your LLM determines whether your tool empowers users or undermines their trust. At GoDaddy (specifically AiroTM) we've seen the power of testing LLMs to help us build reliable and trustworthy AI applications.
In this blog post, we'll discuss the importance and challenges in evaluating LLMs and creating and implementing and effective LLM evaluation blueprint.
Why LLM evaluation matters (and why testing is still challenging)
Testing LLMs differs from checking if a calculator gives the right answer. Language is subjective, messy, and nuanced. Key challenges include subjectivity where many valid answers exist for a single question, hallucinations where LLMs confidently invent facts, scalability issues since human-in-the-loop checks don't scale across thousands of outputs, and actionability problems where reporting "3/5 correctness" doesn't help anyone know what to fix. Additionally, ensuring tests continuously feed back into improving prompts, models, and datasets is a complex iteration challenge.
We've developed an evaluation blueprint that can be used to help solve the challenge of evaluating LLMs.
Streamlined evaluation blueprint
The following diagram shows the complete evaluation cycle, from defining business outcomes to building automated systems that continuously improve.
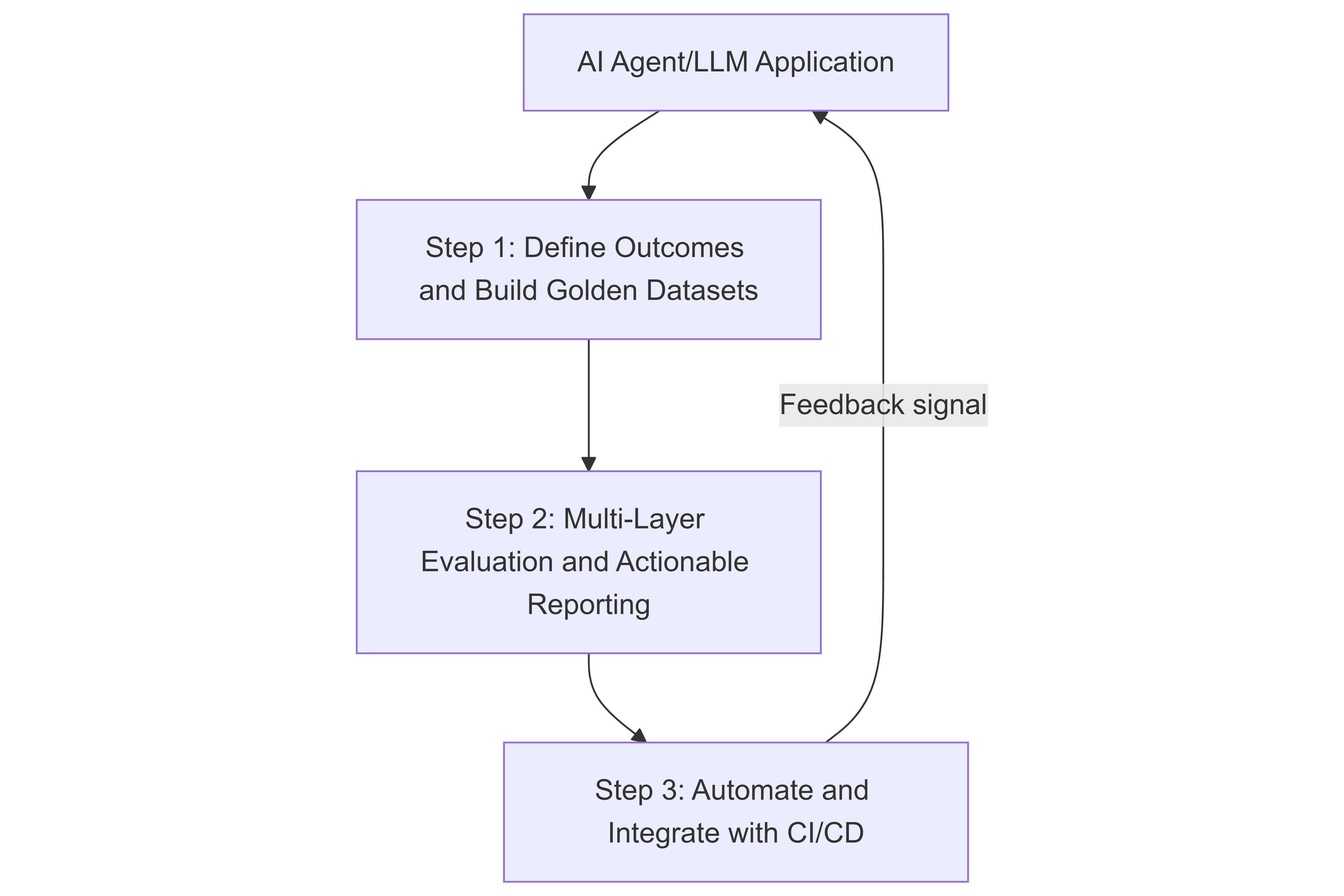
Step 1: Define outcomes and build golden datasets
Success starts by tying business outcomes directly to test data. Don’t treat them separately.
The first thing you need to do is define success criteria. For us, this included things like:
- Domain recommendations converted to domains actually purchased.
- LLM generated content output as accurate, brand-compliant, and actionable text.
- A support chat bot providing improved first-contact resolution rate.
One of the most important aspects of defining success criteria is creating a success criteria document. This document includes one to two measurable goals per use case and is critical to ensure results can undergo evaluation.
After you've defined your outcomes, you need to translate outcomes into test data. This includes things like:
- Building golden datasets that reflect real-world usage and include:
- Historical logs (queries, clicks, purchases)
- Expert-annotated examples
- Synthetic adversarial data and edge cases
- Creating dataset targets, starting with 200 to 500 and scaling to 2000 to 5000 (refreshed quarterly). These dataset targets are:
- stored in version-controlled repositories (Git, DVC, HuggingFace).
- tagged with metadata (intent, difficulty, error types).
Think of this as writing unit tests for LLMs: business outcomes lead to golden examples which enable automated checks.
Step 2: Multi-layer evaluation and actionable reporting
Effective evaluation requires both detecting failures and providing clear guidance on how to fix them. This means building a layered system that catches problems at multiple levels while giving your team actionable insights.
The foundation of robust LLM evaluation lies in creating multiple layers of checks. Start with basic format validation using regex patterns and schema checks to ensure outputs match expected structures. Move up to business rule validation that catches policy violations, forbidden content, and compliance issues. Then implement LLM-as-a-Judge approaches using structured prompts and AI-generated checklists that can assess content quality at scale.
For deeper analysis, implement Fine-Grained Error Categorization (FineSurE) that provides sentence-level diagnostics across faithfulness, completeness, and conciseness. Finally, maintain human-in-the-loop validation for high-stakes use cases where automated checks might miss nuanced issues.
The key to making evaluations actionable lies in how you structure your reports. Every error report should pinpoint exactly where problems occur (like "sentence 3 missing call-to-action"), categorize the type of error (hallucination, entity error, style drift), and suggest specific fixes (expand dataset with counter-examples, refine prompt templates).
Create an Evaluation Playbook that clearly defines what tests run when, who owns each evaluation layer, and how error reports map to specific next steps for your engineering team.
Step 3: Automate and integrate with CI/CD
Transform evaluation from an afterthought into a core part of your engineering pipeline. This means building automated systems that continuously monitor, learn, and improve your LLM applications without manual intervention.
Start by implementing pre-deployment gates that run your golden dataset tests on every pull request. Set up automatic merge blocking when performance regresses more than 5% compared to your baseline metrics. This prevents problematic changes from reaching production while maintaining development velocity.
Establish comprehensive post-deployment monitoring through dashboards that track both technical metrics (precision@k, checklist pass rates) and business outcomes (conversion rates, user engagement). Configure automatic logging of failures into your dataset with weekly review cycles to identify patterns and improvement opportunities.
Build feedback loops that automatically feed every failure back into your system. Use failed cases to improve prompts, refine retrieval strategies, and tune model parameters. Continuously expand your golden datasets to cover new failure patterns as they emerge, ensuring your evaluation system stays current with real-world usage.
Remember that your evaluation system should evolve alongside your application — it's a living system that grows smarter with each iteration, not a static checklist that becomes outdated over time.
Quick checklist for teams
The following is a checklist teams can use when building an LLM evaluation plan:
- Success criteria defined and mapped to golden datasets
- Golden datasets version-controlled and tagged with metadata
- Multi-layer evaluation pipeline in place
- Error reports are localized, categorized, and actionable
- CI/CD integration with regression gates
- Continuous monitoring and dataset updates
Now that we've outlined the blueprint, we'll cover the specific testing techniques that power this system.
Modern evaluation approaches: Blending old and new
Traditional ML testing gave us precision, recall, and other ranking metrics. LLMs do add complexity, but these classic metrics are powerful — especially when combined with modern testing techniques.
Classic metrics for ranking products or information retrieval applications
At GoDaddy, we have already seen them in action for retrieval-augmented generation (RAG), where LLMs fetch supporting documents, and retrieval quality matters as much as generation quality. Some common metrics include:
- Precision@k: Out of the top k retrieved items, how many were relevant?
- Recall@k: Of all relevant items, how many were retrieved?
- Mean reciprocal rank: How high in the list does the first relevant item appear?
These metrics answer: Does the LLM ground its answers on the precise context, or does it drift? You can extend these metrics to chunk precision and recall as you preserve the document ID. One caveat to this assumption is not all chunks match the user query equally, so the assumption will require more work depending on the complexity of the query and knowledge setup.
Two critical modern metrics complement these traditional approaches: context relevance and context sufficiency, as described in RAG testing metrics guide. Context relevance measures how much retrieved information proves actually useful, while context sufficiency measures whether you found enough information to properly answer the question.
Logo keywords
Now let's examine keyword generation using LLMs. At GoDaddy, we use LLMs with optimized prompts and business context to generate keywords that are further processed to design AI logos and provide AI domain name recommendations to our customers. For logo design, we combined traditional ranking metrics with LLM-specific evaluations to create Logo keywords.
We created logo keywords by checking whether usable and appropriate design objects (bridge, sun, wave, paintbrush) appeared in the top 10 or 20 results. Precision at 10 and precision at 20 exposed whether the LLM generated terms designers could act on versus abstract but non-drawable words like empathy, cheer, creativity.
For example, let's say a user wants to design a logo for their art store. We use relevant keywords to create a logo using our image tools. If the keywords are relevant but not helpful (like creativity, color, mindfulness), we wouldn't be able to design a logo for the user, so they're excluded. This is where we optimize the prompt using a golden dataset (devised by domain experts) to ensure the keywords are relevant and useful, optimizing precision and recall metrics.
The key takeaway when testing LLM outputs is don't just measure meaning — measure structure too.
Domain recommendations
For domain recommendations, we use traditional ranking metrics to ensure the domains generated are relevant and valuable. For the golden dataset, we used the existing ML recommender, historical search, and converted domains as ground truth. Therefore, not every case requires a human in the loop. We created a custom test that combined character-level similarity (Levenshtein distance measuring spelling closeness), meaning similarity (semantic similarity capturing concepts like bigstore.com similar to largeshop.com), and real-world performance data from actual customer behavior including search queries, add-to-cart actions, and purchases. This gave us domains that not only made sense but also looked like successful domains.
Our LLM recommender beat the traditional ML system by 15% because it understood both what users wanted and what they actually bought. The test showed us exactly why — better structural matching led to higher conversion rates.
When considering metrics and testing, start with business metrics (conversion, engagement) as your north star, then build technical metrics that predict those outcomes. Don't test in a vacuum.
Effective LLM-as-a-Judge patterns
GoDaddy Airo generates lots of content using LLMs for our customers including social media posts, blog posts, and other kinds of content. Airo can even generate websites using LLMs. All these LLM outputs require quality testing. Testing such LLM outputs often requires going beyond the gold dataset and classic metrics. An LLM-as-a-judge approach means treating the model (or another model) as an evaluator with structured, interpretable criteria. We've developed a framework to test the quality of the content generated by the LLM following two key principles:
- Localization of Errors: Instead of giving a global score (like "3/5"), identify exactly where in the content the problems occur—which sentences, which sections, which specific elements need improvement.
- Categorization of Errors: Classify the kind of error found (entity error, factual error, style issue) so engineers know exactly what to fix and how to improve the system.
LLM-as-a-judge should focus on finding specific (localized) errors in generated content and not global scores.
We use four evaluation methods that make the LLM-as-a-judge approach effective: checklist evaluations, FineSurE, contrastive evaluations, and cost-aware evaluations.
Checklist evaluations
A simple but powerful framework that decomposes complex tasks into a set of clear yes/no checks. Instead of one vague score, a checklist asks whether required elements are present, making results transparent and actionable.
But the real breakthrough here is using AI-generated checklists. Modern LLMs can automatically create tailored testing criteria for any instruction or task. Given a prompt like "generate a marketing plan," the LLM creates a checklist that asks: Did it mention target audience analysis? Did it include at least three actionable channels? Did it consider budget constraints?
The AI-generated checklist approach is based on research from the TICK paper, where you can also find the prompt templates used to generate the checklist itself.
The AI-generated checklist process creates a tight feedback loop: LLMs generate content, an LLM creates testing checklists, another LLM tests the content against those checklists, and results feed back to improve the next generation. No human annotation required, and the system gets smarter with each iteration.
Some AI agents or LLM workflows we have tested using this approach include:
- LLM-generated marketing plans: Did the plan mention target audience analysis? Did it include at least three actionable channels?
- Customer summaries based on past interactions: Did the output reflect the correct portfolio size and TLD trends? (A checklist can surface errors like miscounting domains or language bias).
- Social posts: Did the post use the right tone, storytelling, and call-to-action? (Checklists pinpointed gaps in brand alignment).
The beauty is that each checklist is task-specific and automatically generated — no more generic "rate this 1-5" tests that don't tell you what to fix.
FineSurE
FineSurE is a structured testing approach designed for summarization and similar tasks. It measures outputs along many dimensions — faithfulness (accuracy of facts), completeness (coverage of key points), and conciseness (brevity and focus). FineSurE yields interpretable, sentence-level diagnostics beyond traditional metrics. Go to the FineSurE paper for more details and prompts.
What makes FineSurE powerful is its error categorization system. Instead of just saying "this sentence is wrong," it classifies exactly what kind of error occurred:
- Entity errors: Wrong names, dates, or key facts
- Out-of-context errors: Information not present in the source
- Predicate errors: Incorrect relationships between facts
- Circumstantial errors: Wrong time, location, or context details
- Coreference errors: Pronouns pointing to wrong entities
- Linking errors: Incorrect connections between statements
FineSurE's granular approach helps engineers understand not just that something failed, but why it failed and how to fix it. For example, if your LLM consistently makes entity errors, you know to improve fact-checking. If it makes linking errors, you need better context understanding.
The system works by having an LLM analyze each sentence against the source material and categorize any errors it finds, providing both the error kind and a brief explanation. The error categorization creates actionable feedback for prompt engineering and model improvement.
Contrastive evaluations
For subjective tasks like creative copy, comparing outputs head-to-head revealed which was stronger in engagement or clarity using contrastive evaluations. Contrastive testing proved especially powerful for social posts or marketing copy.
Cost-aware evaluations
Not every test requires a massive LLM. Smaller models offered scalable, affordable ways to judge outputs, especially in frequent, large-scale runs.
Together, these methods turn LLMs into effective evaluators of other LLMs, producing actionable, interpretable signals instead of vague scores.
Conclusion
Testing LLM applications isn't overhead — it's the difference between a toy and a trusted product. As we move toward AI agents and LLM workflows that plan, reason, and take multi-step actions, the testing principles remain the same: build frameworks that provide actionable insights, not just scores. The next evolution is to Feedback Agents that can supervise results and automatically apply fixes. We'll explore this pattern in our next blog.





