
Whether you’re an aspiring entrepreneur, blogger or small business owner, having a website is a must in today’s society. But walking blindly into the world of site creation can be a bit daunting. Fortunately, we’ve got you covered with a detailed list of to-do items to plan a website before you build it yourself or hire a professional to do it for you.
Use this post as a project plan that outlines exactly how to get your new website ready to launch.

Go from idea to online in minutes with GoDaddy Airo™
Get started now.
How to plan a website in 7 steps
Creating a website plan helps you organize your project, collect the assets you need, and start with an outline of your goals and a clear strategy for achieving them.
The website plan will serve as an anchor you can refer to for any later decisions as well as a roadmap that can be used to set deadlines and targets.
Read on for a website plan that will help you launch your site quickly, easily and strategically. If you're still in the early stages, have a look at this guide on how to start a business.
Related: How to build a website
1. Identify your website goals
Before you start building a website, you need to know why you are building it.
- What is your primary objective?
- What do you want your website to accomplish for your business?
- Is it strictly informational, or are you selling products?
- Are you looking to increase engagement with customers via your site?
- Is your goal to leverage your website to bolster year-end profits?
Knowing the answers to these questions will help you create a plan that is strategically tied to your business goals, so it’s important to always start at square one: the purpose of your website.
Start thinking about the broad purpose of your website
The purpose of your website is the reason why you want to build it. It’s the somewhat obvious reason for what you think a website can do for you. You might think the purpose is to:
- Attract traffic and grow an audience
- Showcase your products
- Share what you know
- Advertise your business
- Entertain your readers
While those are good reasons to have a website, they won’t necessarily help you do anything specific, which is why you need to turn the purpose into a concrete goal.
Turn your purpose into a concrete goal
The goal is the real, concrete reason why you want (and need) a website. It’s what you want to happen as a result of having a website.
To find your concrete goal, start with the purpose that seems obvious and then keep asking yourself “why,” until you get to the real purpose. Examples of this might be:
| Broad Purpose | Concrete Goal |
| Attract traffic and grow and audience | Sell an eBook to your audience |
| Showcase your products | Sell more products |
| Share what you know | Build authority and get speaking engagements |
| Advertise your business | Get clients to register for a consultation |
| Entertain your readers | Build your newsletter subscriber base |
As you can see in the examples, this exercise narrows your focus so you can define what you actually want your website to do. You can identify the conversion or action you want your audience to do when they are on your website.
Decide what your website needs to help you reach your goal
Understanding the goal for the website (the action you want to trigger) enables you to start designing a strategy that leads to that conversion.
When you plan a website, look at your goal and determine what your site needs to help you accomplish the objective.
For example, if your goal is to:
- Sell an eBook to your audience — You need to funnel users to your eBook product pages and have a way for them to make their purchase.
- Build authority and get speaking engagements — You need to highlight your expertise through blog posts and authoritative content and create a page that tells audiences why and how to hire you as a speaker.
- Build your newsletter subscriber base — You need to create interesting and engaging lead magnets and add opt-in forms on your site.
Break down your goal, and determine the elements you need on your site (such as opt-in forms, landing pages, etc.) to reach that goal. Then, design a funnel on your site that will drive audiences toward the action you want them to take.
Depending on your goal and business type, also consider your website costs.

2. Identify your target audience
Once you know what you want users to do on your site, you need to figure out who those users are.
It’s critical to clearly identify your website’s target audience when planning your website.
Only then can you create strategic plans to get website visitors to take action.
Why you need to know your target audience
If you’re trying to attract everybody to your website, you’re probably not going to attract anybody. Casting a wide, broad net does little to help with driving traffic, connecting with audiences, or driving conversions. So, you need to know exactly who you are trying to reach.
If you skip this step and fail to clearly identify your target audience, it can lead to a variety of marketing problems.
You won’t know how to talk to your audience. If you don’t know who your customers are and what they like, want and need, it’s difficult to know how to speak directly to them. When you can clearly visualize your audience, it’s much easier to create copy that resonates with them.
You will develop weak, vague branding. Great branding pulls in a specific target audience. If you don’t know your audience, you can’t design your branding to reach them. You will end up creating branding elements that target everyone, which end up being unmemorable, bland and boring.
You will struggle with building lasting customer loyalty and affinity. When your brand and marketing messages are weak and generic, they don’t resonate with customers. If you can’t connect with customers through strong messaging, you will struggle with building lasting brand affinity or loyalty.
You will attract the wrong customers. Vague messaging will not only prevent your target audience from being drawn to your brand, but it will also draw in the wrong type of customers. When your communication isn’t targeting the right audience, you may attract unqualified leads and customers who can’t benefit from your offerings.
You will blend into the competition. When you don’t know who you are trying to attract, you can’t build a brand with a point-of-view. And without a strong brand identity, you risk looking like everyone else in your industry. Your company won’t stand out or connect with customers.
You won’t be able to effectively use targeted advertising. Through targeted social media advertising campaigns, you can choose who sees your ads based on details related to demographics and interests. If you don’t know these things about your ideal audience, you won’t be able to launch effective ad campaigns that target the people most likely to buy from your brand.
Now that you can see why knowing your audience is so important, let’s look at some tips for getting to know your ideal customers.
How to get to know your target audience
You may think you already know who your target audience is. Maybe you have an idea in your head. Unfortunately, that image in your mind might be wrong.
A lot of brands and marketers make incorrect assumptions about their audience.
The only way to truly know who your audience is and what they want, think and need is to do research. To get insights into your target audience, you can do a few things.
Interview your customers. Get to know the people who are already buying from you. Conduct in-person interviews with readers and past customers and shoppers.
Interview your ideal buyers. Get to know the people you want to sell to. Identify people who would be your ideal customer and interview them as well.
Send out surveys. Collect feedback in a more streamlined way by sending out small surveys to your past customers and email subscribers.
See what customers are saying online. If you can’t get customers to talk to you, go to the places where they share their opinions online. Engage in social listening by browsing hashtags related to your brand or industry, and visit review sites to collect feedback.
See what your business data says. Business data is information about the products and services you sell as well as how customers engage with your offerings. Knowing what you sell, when you sell it, how often people buy and similar information will help you get to know your customers and see how they make purchasing decisions.
See what your website stats say. Google Analytics offers insights into how your customers use your website. Use your website data to see what pages customers visit, how often they visit your site before they buy and other metrics to get to know your audience.
Once you collect this information, you will get a better idea about who your customers are and what is going on in their heads. From there, you can create a clear and detailed description of your customer, also known as a buyer persona.
How to create a buyer persona

A buyer persona is a semi-fictional character you create to represent your ideal customer. It is a description of an imaginary customer who meets the criteria of your target audience.
To build a buyer persona for your brand, imagine your ideal buyer and then fill in the following information that describes him or her:
Demographic details
- Age
- Gender
- Income
- Location
- Family situation
- Annual income
- Education
Professional details
- Industry
- Job title
- Company size
- Professional goals
Psychographics
- Personality traits
- Values
- Attitudes
- Interests
- Subconscious and conscious beliefs
- Motivations
- Priorities
Influences
- Favorite blogs/websites
- Favorite magazines/books
- Favorite thought leaders
Beliefs / Goals
- What do they believe strongly in?
- What are the characteristics of their personality?
- What are their personal goals?
Challenges
- What keeps them up at night?
- What are their pain points?
- What challenges are they facing?
Buying process
- What is their role in the purchase process?
- How do they regularly buy?
- What are their objections to purchasing?
By filling in these details, you create a customer profile that describes your ideal buyer. Then, you can bring the details to life by turning it into a narrative that tells a story about your target customer.
Don’t just describe the persona as a list of details. Add a photo to the story and write a few paragraphs about who they are and what they need.
Having a narrative and photo of your target audience will make it easier to shape your marketing messages. You will keep this image in mind as you create your website.
3. Define your unique selling proposition
So far in your process of planning a website, you’ve determined your goals and defined your target audience. Now, you can start developing marketing strategies for reaching the audience and encouraging them to act.
The first step in that process is creating a unique selling proposition.
What is a unique selling proposition?
A unique selling proposition, or USP, is something special that makes your brand, products or services different from and/or better than your competitors.
It explains the selling points that get prospects to act and take a step closer to becoming your customer.
It grabs the attention of your ideal customers and is the reason why they choose you over all others.
You need to know your USP as you plan a website because your site will be positioned around your unique selling propositions. All of your copy and content will be positioned to subtly (and sometimes not so subtly) promote your USP and tell website visitors why they should choose your brand.
How to develop your unique selling proposition
To develop your unique selling proposition, think about your brand, products and services and answer the following questions.
- How are you different from your competitors?
- Why does that difference matter to customers?
- What specific benefit do customers get by choosing you over the competition?
- Why does that benefit matter to customers?
Don’t rush through this exercise. The things that immediately come to mind might be too obvious. Spend time really digging into how your offerings truly help your customers and solve their problems.
Related: How to find inspiration from your competitors (without stealing their ideas)
Tips for finding your USP
If you’re having a difficult time identifying your unique selling proposition, use the following tips for help.
- Think about what your customers value and how you help them get those things.
- Think about the problems your customers have and how you help solve them.
- Consider the unique strengths your brand brings to the table.
- Look at your competitors to see how you can differentiate your brand.
Remember, unique selling propositions aren’t specific to eCommerce sites and service-oriented businesses. If you’re a content creator or blogger, you’re “selling” information and want to establish yourself as a thought leader. The questions still apply — what are you doing to set yourself apart from the crowd?
For more tips, use this guide on finding your unique selling proposition.
4. Secure a domain name and hosting
Now that you have finished a big portion of your website plan, you can get ready to set up your site. Start the process by securing a domain name and hosting.
What is a domain name and hosting?
For a website to show up online, it needs both a domain name and hosting.
- A domain name, also known as a URL (Uniform Resource Locator), is a web address used to locate and access a website on the internet.
- Website hosting is the server space and resources that store a website’s files and data.
Think of it this way: Your website is like a house. Your web hosting is the land the house sits on. And the domain is the street address.
You have many options for purchasing domain names and website hosting. The two items can be purchased from separate companies or purchased together. GoDaddy offers both domain names and website hosting, which can be purchased together or separately.
Domain names and hosting may also be purchased along with website builder solutions — like GoDaddy Website Builder (more on that later).
Domain names and web hosting packages are purchased for set periods of time, and their pricing varies depending on a variety of factors. Domain name costs typically range from $2 to $20 per year and hinge on factors including the demand/popularity of the domain name and/or its extension. Hosting costs have a wide range of pricing. Costs can start as low as $2.99/month and go up depending on the amount of website traffic you expect, the complexity of your website, and the features you’d like to add.
Related: What is web hosting?
Choosing a domain name
When you choose a domain, you have two pieces of the domain to consider — the custom phrase that comes before the “dot” and the domain extension. The domain extension includes the “dot” and the letters after it. In these examples, the domain extension is in bold.
- domainname.com
The most common domain extensions are .com, .net, .info, .co and .org. These were the first domain extensions that existed, which is why many sites use them. They are also in high demand because they are the most recognizable.
There are also hundreds of new domain extensions known as generic top-level domain names (gTLDs). You can choose domain extensions that are highly relevant for your brand, such as:
- domainname.guru
- domainname.nyc
- domainname.photography
- domainname.marketing
- domainname.consulting
To learn more about these, check out our domain extensions guide here.
When you choose a domain for your site, you will need to come up with the phrase that comes before the “dot” as well as the extension that will come at the end of your website address.
Related: How to choose a domain name
Purchasing a domain means you register the domain for a set amount of time. You don’t buy it and own it forever. You need to continually renew the domain over the time that you want to keep and use it.
5. Pick a website builder
At this point in planning, you’re ready to choose how you will build your website.
You have a few options for building your site. You can:
- Use a drag-and-drop website builder like the one from GoDaddy (take advantage of the power of AI website builders).
- Use a more advanced content management system like WordPress that requires a bit more technical know-how (although GoDaddy's WordPress Hosting makes starting a WordPress site much easier).
- Use custom code and start from scratch rather than using a pre-designed template.
- Hire a professional web designer to do it all for you.
As you plan a website, take a closer look at what type of builder will best suit your needs. Ask yourself the following questions to get an idea about your needs.
- Do you want to blog?
- Do you want to collect visitor information?
- Do you want to sell products or services?
- Will you accept electronic payment?
- Will you use a calendar or schedule appointments?
- Do you want to track inventory and shipping?
- Do you want total control over the site’s code?
- Do you prefer an easy-to-use builder?
- Are you going to hire a professional?
- Are you going to design on your own?
- What’s your budget?
These answers will help you determine the platform that will work best for you.
Option 1: Drag-and-drop website builder
Website builders help you develop websites without extensive coding or technical skills. Builders provide a user-friendly interface that allows you to design, customize, and publish websites using pre-designed templates, drag-and-drop tools, and artificial intelligence (AI).
With a website builder, you choose a theme (a premade website design) and customize it to suit your needs. You can add structural components (such as spaces, dividers, background images, custom headings, footers and menus) and design elements such as:
- Images
- Videos
- Text blocks
- Titles
- Galleries
- Forms
- Slideshows
- Buttons
With the introduction of AI tools, website builders can now aid you in the process of creating your site. During set-up, you provide answers to prompts about your type of business, website goals, and business information (such as contact information and details about products and services), and the website builder will deliver a site that matches your criteria.
You can then customize the site using drag-and-drop elements and by adding your own branded elements such as images, color palettes, and fonts.
GoDaddy Website Builder uses both AI and drag-and-drop features to help you easily create a website. With its swipe-to-style interface, dozens of industry-specific themes, professionally selected photos and more, you’ll have everything you need to build a site. GoDaddy’s solution is cost-effective, incredibly easy to use, and comes with many built-in features — like SEO tools, SSL and email marketing. Even better? You can try it first for free.
If you’re short on time (or money) or simply don’t want to add “web design” to your already overflowing plate of tasks, then a site builder might be in your best interest.
Related: Compare the top website building providers

GoDaddy Website Builder offers beautifully designed templates for myriad types of sites.
Option 2: Content management system (WordPress)
If you want more options and customization than what is available with a website builder, you may want to choose a more robust content management system (CMS) like WordPress.
Building a website using WordPress provides a balance between ease of use, flexibility and scalability.
Creating a website using a CMS like WordPress requires some intermediate tech skills. If you choose to go with the free version of WordPress, you’ll need to purchase a hosting account and install the WordPress files. You’ll also be tasked with installing plugins and maintaining your site’s security through any necessary software updates, backups, etc.
If you want the customization and functionality that a WordPress site offers but don’t have the time or skills to handle the more technical aspects of creating and maintaining a WordPress website, a solution such as GoDaddy’s WordPress Hosting could be the answer.
GoDaddy’s WordPress Hosting comes with WordPress, plugins and design themes built-in. It supports ecommerce and offers a variety of tools and specifications that keep your site secure and running speedily and smoothly.
A WordPress CMS also offers builders and themes that make creating your site easy, while also offering the flexibility for customization if you want and need it. Browse the theme gallery for GoDaddy Managed WordPress Hosting to view customizable themes available for just about every kind of website.
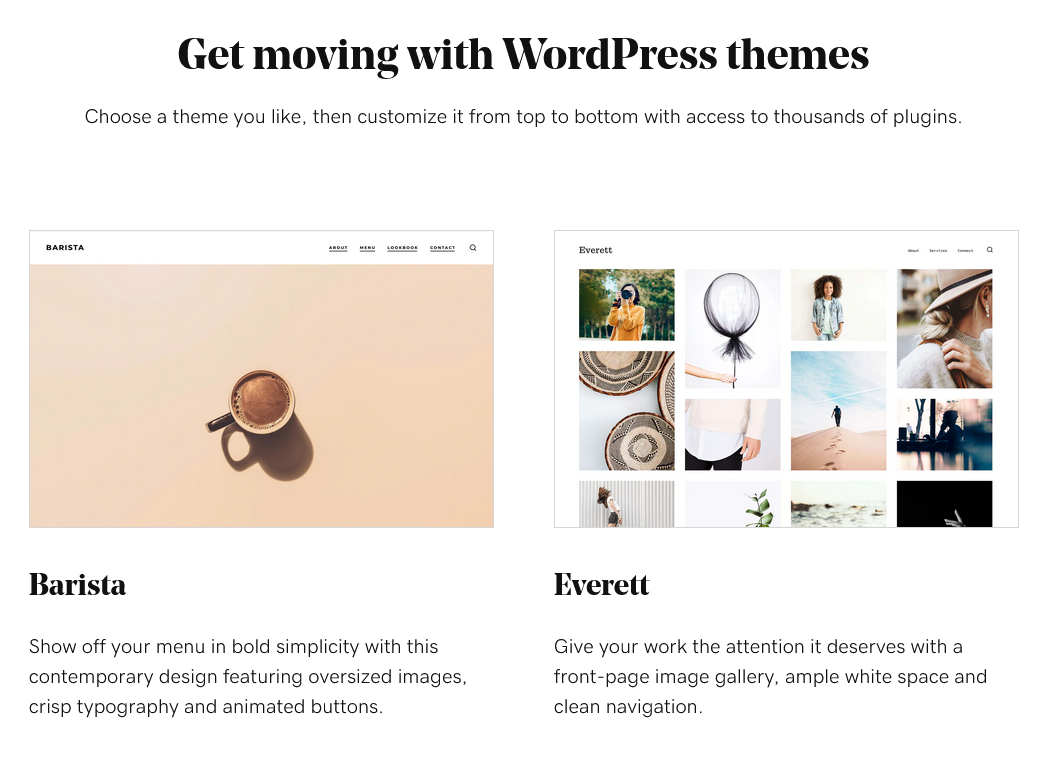
Option 3: Custom code
If you want the ultimate flexibility for your website, you can build it with custom code. But coding your own website requires specialized knowledge and is usually impractical for entrepreneurs who aren’t in the coding business.
To go this route, you need to use a web programming or scripting language that provides instructions for either the “client” side (a user’s web browser) or “server” side (the server where your site’s files are stored). Those languages include:
- ASP/ASP.NET
- CSS
- HTML
- JavaScript
- Perl
- PHP
- Python
- Ruby on Rails
- XML
The operating system of your hosting account determines which languages you can use so if you choose to go this route, be mindful of what language you want to use when you purchase hosting.

Option 4: Hire a professional website designer
If you don’t want to go any of these routes, you have one other option. You can hire an expert web designer to create your website.
A professional web designer will take the information you have collected and construct your site for you. That site may be built through one of the options mentioned above. The designer may use a website builder, content management system or custom code for your site. The price of your site will be more expensive for custom projects and less expensive when designers use prebuilt themes and drag-and-drop tools.
Ask the designer what they will use to build your site to get an idea about their work, experience and pricing. Also, keep the following questions in mind as you research to find the perfect designer to work with.
- Has the designer committed to a career in web design?
- Does the designer provide direct access to their completed work?
- Are they good at communicating?
- Do they have references?
- Do they have a portfolio?
- Do you like their portfolio?
- Are their previous projects high-quality?
Before you hire a designer, get to know them and their work to make sure they are the right person for the job.
The pros at GoDaddy's Website Design Service can build a mobile-friendly, modern WordPress website that reflects your industry while following your lead and input. Check out the design gallery.
Once you’ve determined the type of platform you’re going to use, it’s time to start creating design elements. Go through the rest of this website plan post to make sure you have all of the strategic design and copy ideas you need to launch the right way.
6. Create and collect design elements
By now, you have a strategy, domain name and platform for where you will build your site. The next step in this website plan is putting together the content you need to fill your site. Start this process by creating and collecting design elements.
Create and collect brand design elements
Brand design elements are graphical representations of your business. They are the design elements that help customers get to know and remember you. These design elements define your brand personality and help customers feel what your brand represents through the use of:
- Colors
- Fonts and typography
- Logos
- Images and photos
If you aren’t sure what this means, look at competitor websites and sites you love for inspiration, in addition to website themes and templates available in website builders. For a more structured resource, check out our guide on how to make a logo, we offer best practices and step by step instructions on how to choose a font, colors or the type of logo that works best for your business.
Pay attention to how other companies use branded design elements to tell a story about who they are.
Once you decide on the elements you will use to graphically represent your brand, outline all of these elements and standards in a brand style guide. When you have a brand guide, you can create consistency across your website and all of your other marketing materials as everyone on your team will have a guide to direct the look and feel of your content.
Related: How to choose brand colors and use them on your website
Pick out a theme/template you like
Even if you aren’t going to use a theme for your website, you can benefit by browsing through theme showcases.
The best way to figure out what you want out of your site is to look at what else is out there.
You can identify what you like and what you don’t and then use that in your development process.
If you are building your site using WordPress or a website builder, pick out a theme/template. Note that you don’t have to use the exact look of the theme. There are ways to customize the style and design to match your branding and preferences.
If you are hiring someone to build your site or doing custom coding, pick out two to five themes that have elements (such as color schemes, layouts, functionality, fonts, etc.) that you would like to see on your site. Provide these themes to your designer to show them what you like or don’t like. Or, use them as inspiration if you choose to code your site yourself.
Create and curate images

Images on your website are just as important as the copy that fills your pages. They visually display your offerings and help audiences get to know you.
Create and curate images that accurately and effectively represent your brand, products and services.
If you have products, take professional, high-quality photos of each item. Get three to four shots of each product to show it from different angles. Customers want to see what they are going to buy, so product images will be vital for driving sales and interest on your website.
If the website is about you (for example, a personal or professional blog, consulting website, etc.), get a few high-quality photos of yourself. Make sure whoever is taking the photos understands that you will be using these on a website. You will want a variety of shots and angles. The best photos for service professionals include a few shots where you (or your staff) are near the edge of the frame as well as in the center.
If you are selling a service that has an end result, take photos of your finished work. This would include screenshots if you are a designer or photos of a completed project if you are an artist.
If you are selling an abstract idea or lifestyle, find stock photos (that don’t look cheesy) that represent the feeling you want people to have about your brand.
If you can’t find existing images to capture your brand, hire a graphic designer to create custom designs for you. Or explore your options with AI-powered image generators that can produce graphics and illustrations based on your directions and descriptions.
Create a file with all of your brand design elements and photos so it will keep them organized until you are ready to start putting your site together.
Related: Create eye-catching imagery for your brand
7. Create content for your core website pages
Now you have a plan for your website and almost everything you need to build it. You just need one final thing — your copy.
For a standard website, you should have content prepped for five key pages: the home, about, product/service, testimonial/review and contact pages. If you plan to have a blog on your site, you should also have at least one blog post ready to go.
Here are a few tips on creating the content you need on your site.
Home page
The home page is your first opportunity to tell your story and start driving website visitors toward the end goal you set out for the site (to get them to join your list, buy a product, etc.).
Lay out your home page content so it introduces who you are, what you do and how you help. This starts to lead visitors down your conversion funnel.
As you create your home page content, remember to:
- Keep it simple. Don’t go into too much detail. Use short, scannable blurbs and then drive users to longer pages for more information.
- Put important information first. Users typically don’t scroll very far down the page so put all of the most important information near the top of the homepage.
- Explain how you help. Catch attention right away by clearly stating what you do and how you help your audience solve a problem.
- Present your unique value propositions. Immediately show what makes you different from competitors.
- Include calls-to-action. Design strategic calls-to-action that move users through your site toward your end goal.
About page
Your about page is a chance to go deeper into who your brand is, what you do and why you do it. Tell a story that answers the following questions:
- Who is the site for?
- What can visitors do on the site?
- Why is the site different from others like it?
- Why did you start this venture?
- Was there a moment or event that sparked your desire to bring your idea to the web?
Your about page will likely be one of the most visited pages on your site. So, if you are rushing to launch, get something up quick. But then when you have more time, go back and spend time fine-tuning your about page.
Product/service page
It’s likely that you are using your website to sell something, whether it is a service that clients must call to schedule or a product that customers can buy directly on the site. So you must have a landing page for your services or an ecommerce product page for your items for sale.
Use this page as an opportunity to showcase and promote your offers and provide:
- Information: general details about the product/service
- Assurance: the reasons why customers will benefit from the product/service
- Motivation: words that guide interested prospects to the next step toward doing business with you
Related: How to strategically use copy and visuals on product landing pages
Testimonial/review page
Customers need to learn to trust your brand before they will choose to do business with you.
You can build that trust by creating a page filled with customer testimonials or reviews.
Reviews and testimonials connect with readers in ways that sales copy cannot because the messages are authentic views of other people’s experiences with your brand.
Related: How to ask for testimonials and reviews from your clients
Contact page
The contact page may feel like a boring, afterthought page, but it is one of the most visited pages on a website. Plus, it’s usually one of the first touchpoints that customers encounter when they decide they are ready to work with or buy from you. So don’t overlook this page.
Starter blog posts

If you choose to add a blog to your site, it helps to have some content ready to go so you aren’t left with a blank blog page. Here are two types of posts to get you started.
Write a post about your launch. Tell readers about you, your inspiration, and what you hope to accomplish with your site. By welcoming readers and introducing yourself, you will start to build your relationship early on.
Write your first blog installment. Now that you’ve introduced why your site exists, write another blog post that will show readers what they can expect to find there in the future. Write a post that is an example of the type of content your readers can come to expect from your site.
Create your copy
If you choose to write the content yourself, read up on copy and blog writing best practices. Get tips for how to write a blog post that is engaging, interesting and formatted for online readers. Learn copywriting tips that help you write landing page copy that leads audiences through your online sales funnel and converts them into customers.
Consider supporting your copywriting efforts using AI content generation tools like ChatGPT and Copy.ai. Copy generators can help you come up with ideas, create first drafts, improve your copy and check for grammar errors. Just remember that you can’t rely 100% on AI-generated content. AI copy may include inaccuracies and bias. The copy may also not fully reflect your brand voice and tone, so always have a human review and revise copy produced by AI tools.
If you don’t have the time or inclination to write your own website content, consider hiring a freelance writer to help you create awesome website content. Work with a writer who understands the importance of CTAs on each page and on-site SEO, and collaborate to create guidelines and outlines so your brand and business is accurately reflected on every page.
Put your website plan into action
Phew! Now, you have everything you need to plan a website and start to build it.
This post helped you create a website plan template that:
- Identified the goals for your website
- Identified your target audience
- Defined your brand’s unique selling propositions
- Secured a domain name (and hosting) for your site
- Planned the best way to build your site
- Created and collected the design assets you need
- Created the copy content you need
Now all that’s left is putting your plan to work. Take the next steps to bring your business, idea or project to life and launch your site! Also, check out our video list on how to plan a website with GoDaddy, for a different view.
Get the tools you need to get your business online — including the right domain name, website builder and our AI-powered solution GoDaddy Airo — at GoDaddy.
*AI-assisted full website including all of the premium features like online store, appointment scheduling, and marketplace selling to name a few, requires paid subscription.
Social media marketing calendar available with GoDaddy Airo, some features will require paid subscription.
Professional Email through Microsoft Office 365 30-day free trial with an option to renew into a paid subscription beyond the promotional period.
While the LLC starter plan is free, there are likely some state and/or local filing fees associated with your filing which will be determined during the filing process.






